
Inhaltsverzeichnis
Einleitung
Ich hatte bereits versucht, meine Logs vom HAProxy im ElasticSearch einzubinden. Nativ war das nicht möglich. Also habe ich im letzten Artikel einen Logstash-Service installiert. An diesen kann ich meine Logs senden. Logstash soll diese nun aufbereiten und an ElasticSearch schicken. Dieses Parsing wird mit Grok vorgenommen, einer Art Regular Expression Notation, die zum Filtern und Werte-Extrahieren verwendet wird.
Der Artikel gehört zu meiner Serie „Bereitstellung eines Elastic SIEM„.
Vorbereitung im HAProxy meiner PFSense
Zuerst muss ich meine Log Source anschließen. Dann kann ich mir die verschiedenen Log-Strings ansehen und überlegen, welche ich wie parsen möchte. Ich verbinde mit mit meiner PFsense und navigiere zu den Settings vom HAProxy:
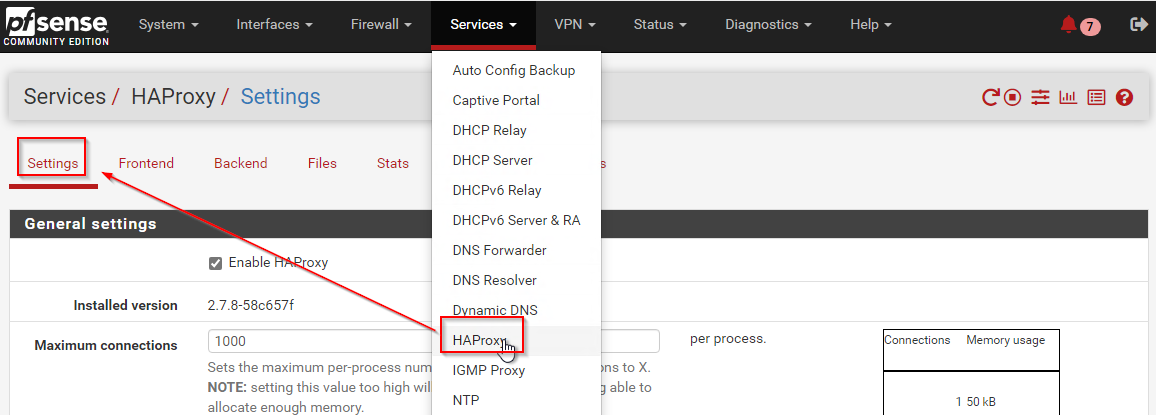
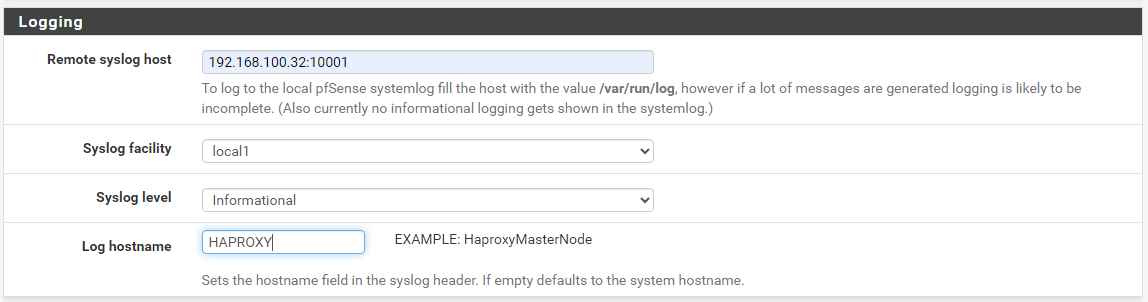
Ich suche nach dem Bereich Logging und gebe dort die IP und den Port meines Logstash-Services ein. Zusätzlich trage ich noch den Namen des Services ein. Vergesst dabei den save-Button am Ende der Seite nicht!
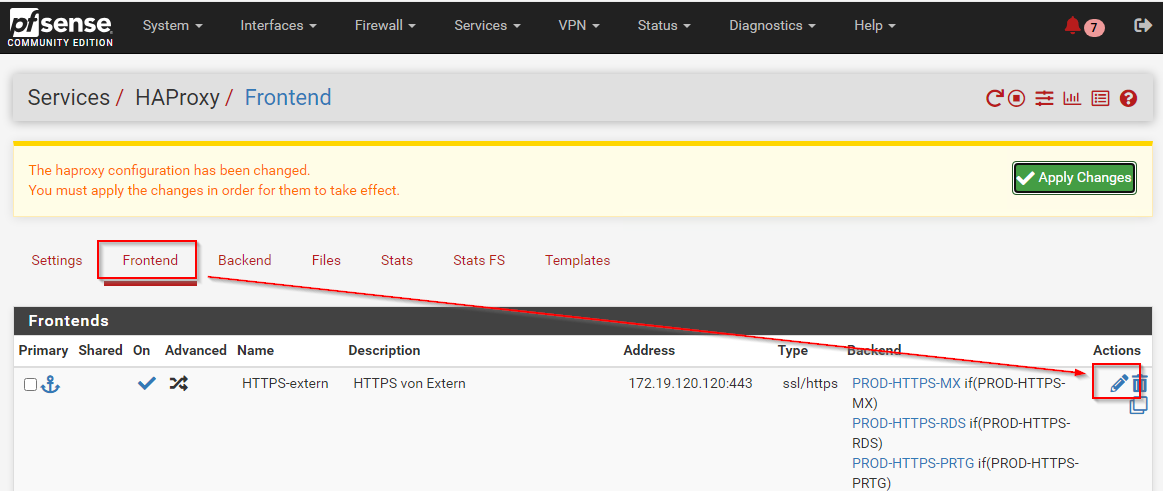
Ich hätte gerne ausführliche Logs vom HAProxy geliefert bekommen, in denen z.B. auch die Namen der Frontends und Backends mit drin stehen. Dies muss für jedes Frontend einzeln aktiviert werden:
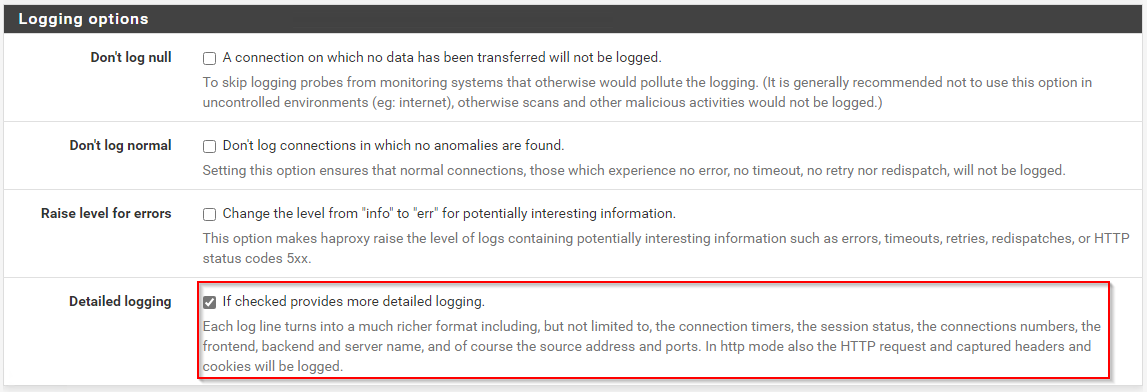
Hier finde ich die Option zum Aktivieren des detaillierten Loggings. Auch hier dürft ihr jede Seite mit dem save-Button am Ende bestätigen:
Zum Abschluss bestätige ich die Konfigurationsänderung mit „apply changes“
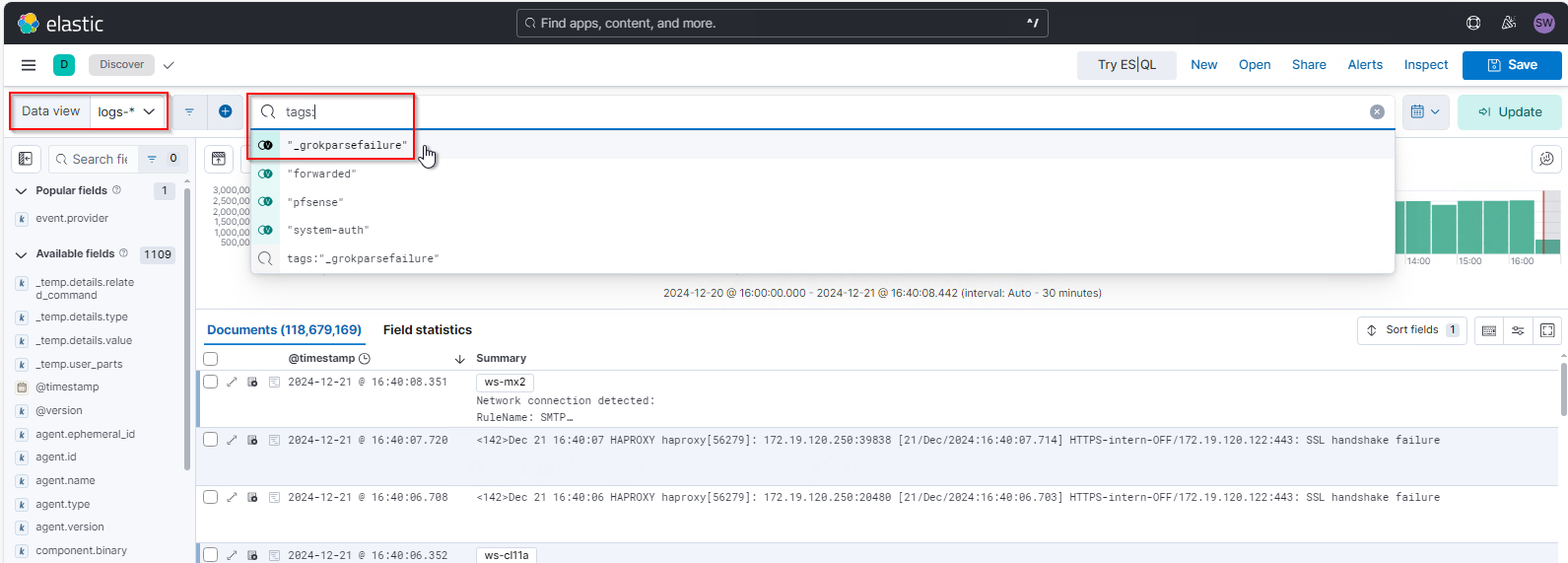
Nun muss ich die Logs im Elastic finden. Dazu navigiere ich in Analytics/Discover, wechsle in die Anzeige für logs* und aktiviere den Tag-Filter für „_grokparsefailure“. Das sind die Events, die ElasticSearch nicht verstanden hat und deren Inhalte somit auch nicht extrahieren konnte:
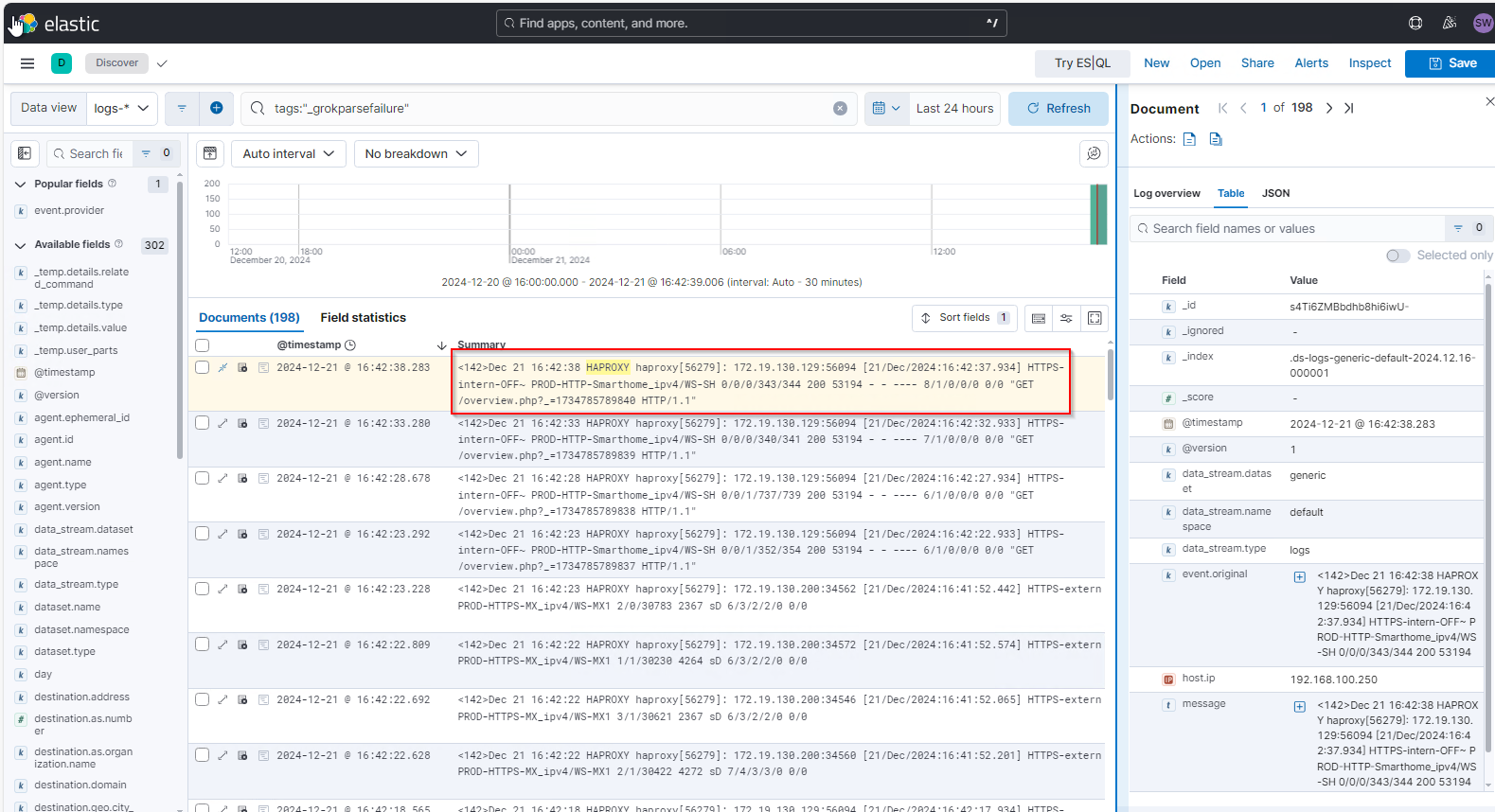
Hier finde ich sofort meine neuen Logfiles wieder 🙂
Die Vorbereitung ist damit abgeschlossen.
Analyse des ersten Message-Strings
Weiter geht es mit dem Parsing. Im letzten Bild sieht man deutlich, dass nur Basis-Properties für die Events angezeigt werden. Die meisten Eigenschaften wurden aus der „message“ nicht extrahiert – ElasticSearch kennt dieses Logmuster nicht und kann daher den Text nicht durch ein Parsing zerlegen. Hier muss ich im Logstash nachhelfen. Ich sehe mir den ersten Message-String einmal genauer an:
<142>Dec 21 16:42:38 HAPROXY haproxy[56279]: 172.19.130.129:56094 [21/Dec/2024:16:42:37.934] HTTPS-intern-OFF~ PROD-HTTP-Smarthome_ipv4/WS-SH 0/0/0/343/344 200 53194 - - ---- 8/1/0/0/0 0/0 "GET /overview.php?_=1734785789840 HTTP/1.1"Der String ist eine Aneinanderreihung verschiedener Eigenschaftswerte. Das Muster dabei ist immer gleich. Ich benötige nun die Bedeutung dieser unterschiedlichen Werte. Das werden dann die Property-Names. Einige Werte habe ich aus dieser Seite bezogen: Introduction to HAProxy Logging
| Property Name | Wert |
| ? | <142> |
| Timestamp des Events | Dec 21 16:42:38 |
| LOG-HOSTNAME (so habe ich den in der PFSense hinterlegt) | HAPROXY |
| Prozessname und ProzessID in der PFSense | haproxy[56279] |
| Source IP | 172.19.130.129 |
| Source Port | 56094 |
| ? | [21/Dec/2024:16:42:37.934] |
| Name des Frontends | HTTPS-intern-OFF |
| Name des Backends / Zielsystem | PROD-HTTP-Smarthome_ipv4/WS-SH |
| Timers* | 0/0/0/343/344 |
| HTTP Statuscode | 200 |
| Bytes count | 53194 |
| – | – |
| – | – |
| Term Code | —- |
| Connection count | 8/1/0/0/0 |
| Queue length | 0/0 |
| Method & Path & Query | „GET /overview.php?_=1734785789840 HTTP/1.1“ |
Grok ist nun eine Art Beschreibung, welcher Bestandteil in dem String in welche Property geschrieben werden soll. Dabei kennt Grok verschiedene Musterbeschreibungen, die das Parsen vereinfachen sollen. Den Parsing- und Filterstring kann man so einfach zusammensetzen. Nur wenn die empfangene Message dem Filter entspricht, wird sie auch in ihre Bestandteile zerlegt. Auf diese Weise können auch mehrere unterschiedliche Message-Strings richtig erkannt und verarbeitet werden.
Parsing mit Grok
Aufbau des Grok Patterns für mein HAProxy Message-String
Für die Fehlerminimierung gibt es im Kibana einen Grok Debugger. Diesen findet man unter Management/Dev-Tools. Hier kann man einen Message-String eintragen und den dafür erforderlichen Grok Pattern Stück für Stück zusammensetzen:
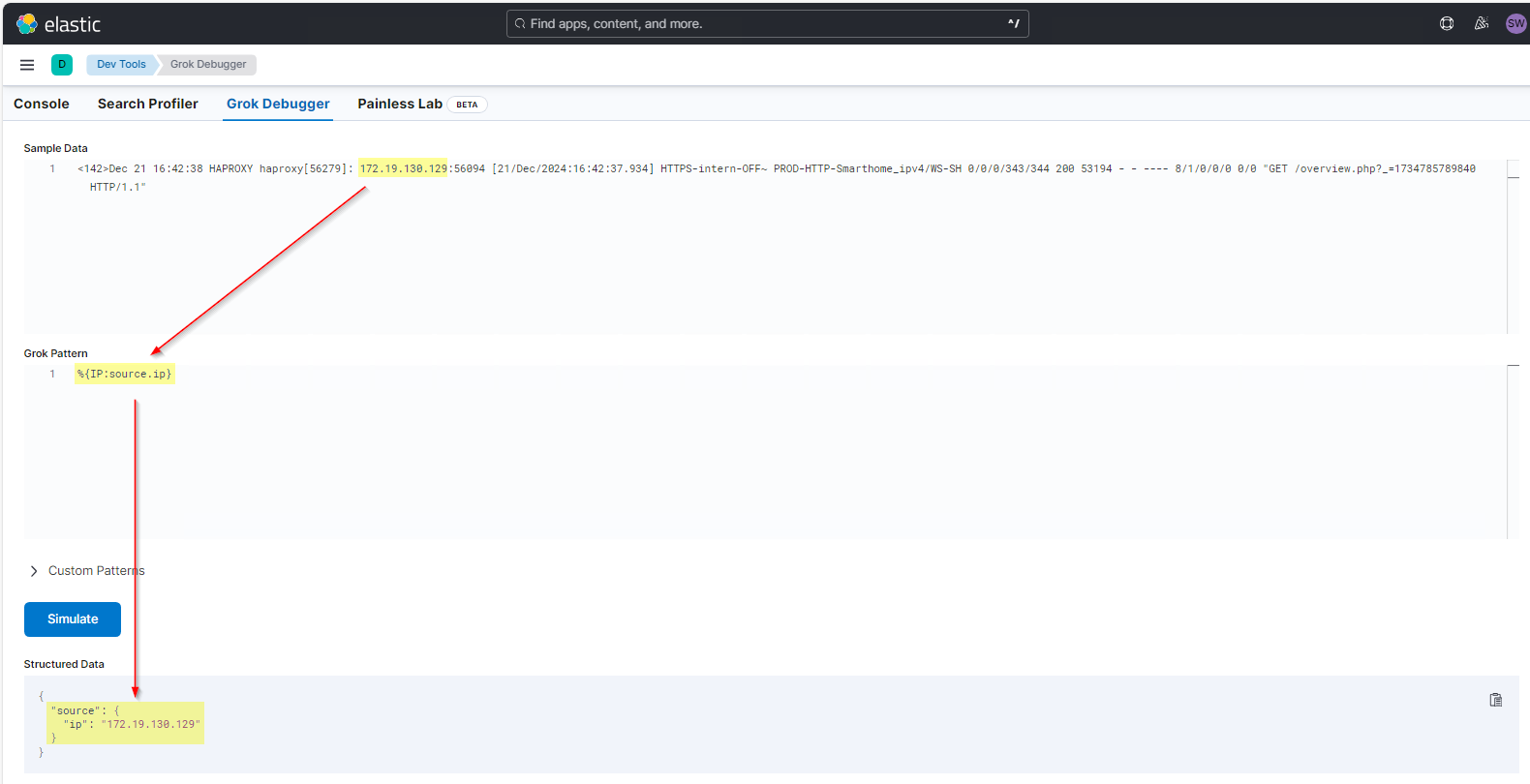
Der Grok Pattern muss von links nach rechts den Message-String verarbeiten. Ich beginne mit der Source IP des Clients. Hier benötige ich den Pattern für eine IP-Adresse und den Namen der Property im ElasticSearch: %{IP:source.ip} Mit dem Prozentzeichen und den geschweiften Klammern wird die Mustersuche eingeleitet. In den Klammern steht zuerst der Mustername IP und durch einen Doppelpunkt abgetrennt der Name der Ziel-Property.
Dieses Pattern trage ich in dem zweiten Feld ein. Mit „simulate“ kann ich das Verhalten des Filters und des Parsers prüfen. Das funktioniert schon mal. Die erste IP(v4) im Message-String wird als source.ip extrahiert. Der Text davor wird ignoriert:
Weiter geht es mit dem Source-Port. Der steht hinter der ersten IPv4. Dazwischen steht aber noch ein Doppelpunkt. Ich muss also den Doppelpunkt als Textzeichen und ein weiteres Pattern hinzufügen. Da der Port immer eine Zahl ist, kann ich hier %{NUMBER:source.port} verwenden. Im Ergebnis schaut das dann so aus:
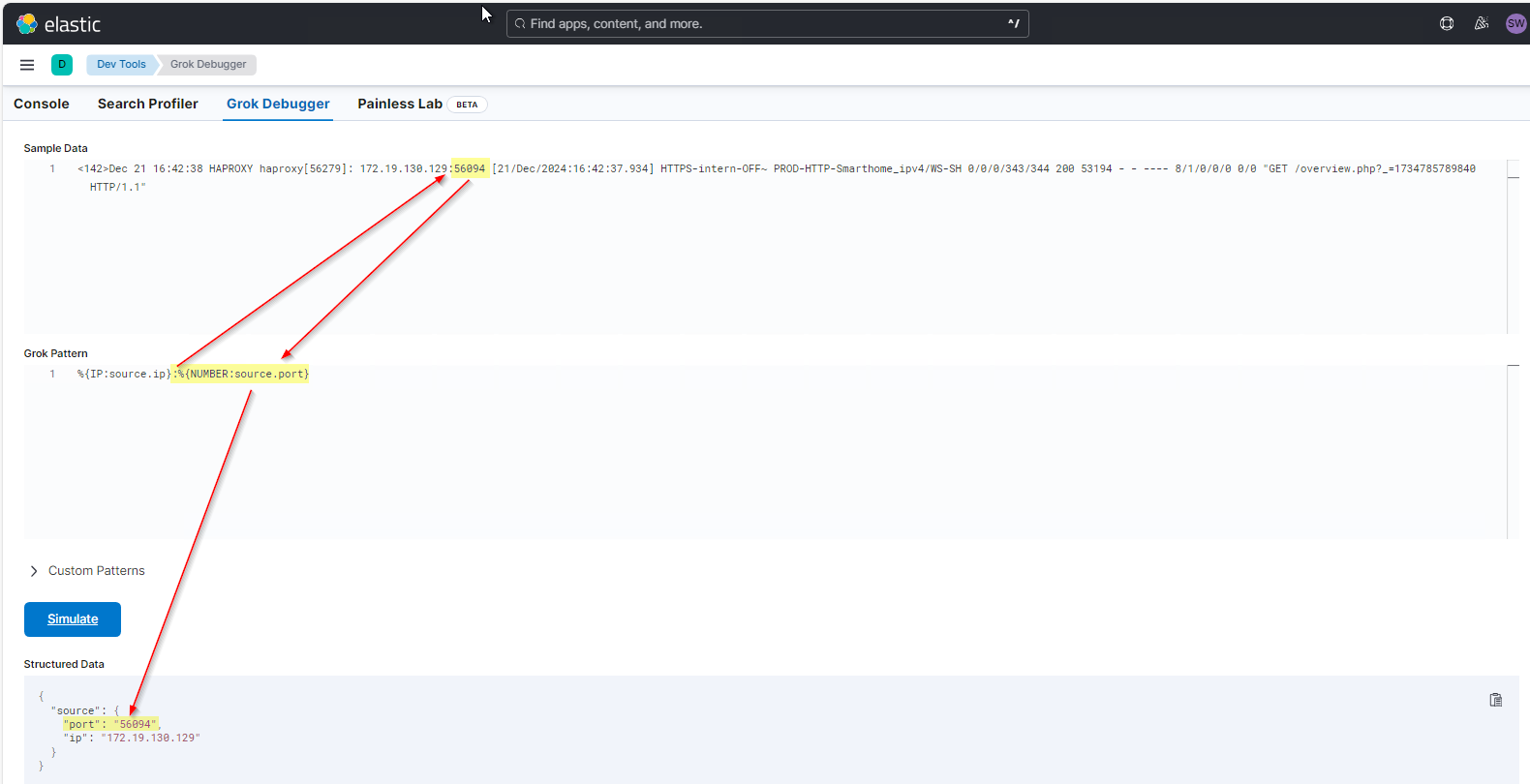
Der Doppelpunkt wird also nicht mit extrahiert, muss aber zur Mustererkennung mit im Grok Pattern enthalten sein! Weiter geht es mit dem Datums-String in den eckigen Klammern. Wenn ich den brauchen würde, dann könnte ich folgende Patterns verwenden:
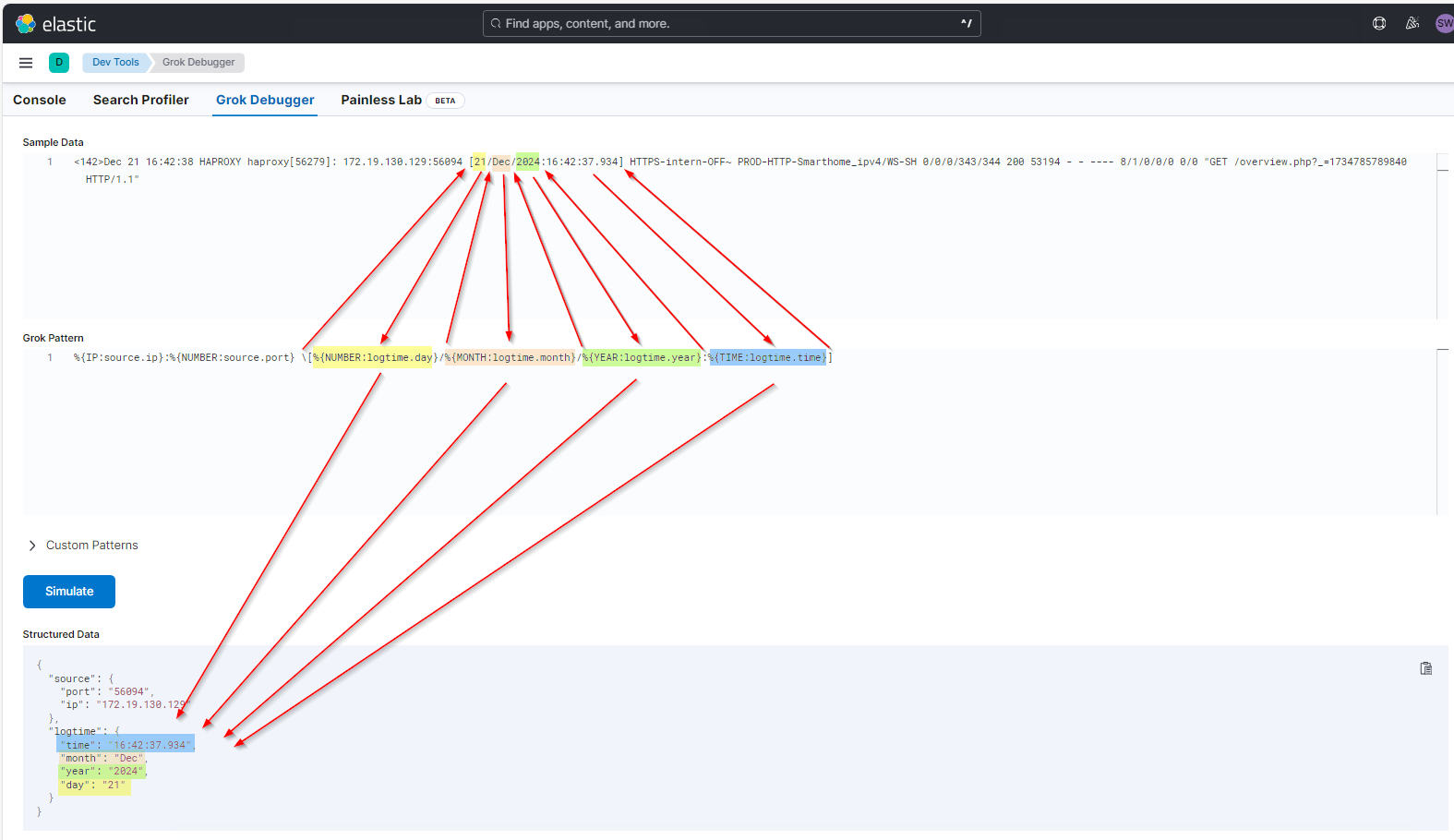
\[%{NUMBER:logtime.day}/%{MONTH:logtime.month}/%{YEAR:logtime.year}:%{TIME:logtime.time}]
Die öffnende Klammer hat in Regular Expression eine besondere Bedeutung. Wenn ich sie aber als Texterkennungszeichen notieren will, dann muss ich sie mit einem Backslash davor „escapen“. Die anderen Patterns kann man im Bild gut nachvollziehen. Beachtet bitte die Trennzeichen zwischen den Patterns:
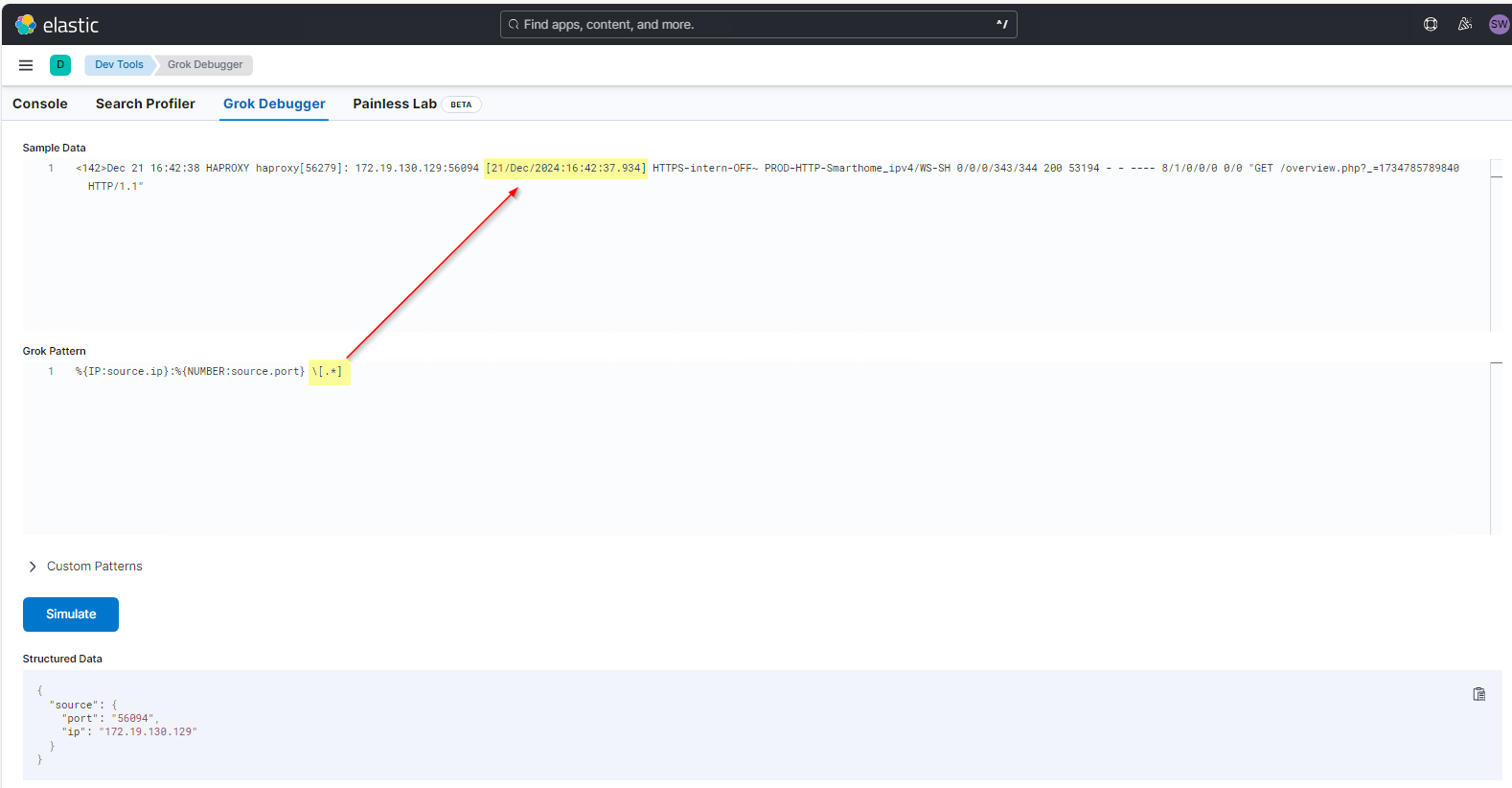
Ich benötige das Datum aber eigentlich nicht, da ElasticSearch das Logdatum ja eh schon kennt. Daher würde ich lieber ein Pattern notieren, um den Teil zwischen den eckigen Klammern zu überspringen. Das sieht dann so aus: \[.*] Ohne den Term mit %{} wird hier keine Eigenschaft entnommen. Die öffnende, eckige Klammer muss ebenfalls escaped werden. Und zwischen beiden Klammern nehme ich den gesamten Text mit .* auf bis zur schließenden, eckigen Klammer:
Die nächste Property ist der Name des Frontends. Dieser ist ein Text. Und Text extrahiert man mit @{DATA:frontend.name}. Wenn man das so eingibt, dann wird aber nur ein leerer Text in der Property ausgegeben. Lasst euch davon nicht beirren: DATA braucht einen Abschluss! Und den habe ich nicht mit angegeben. Beachtet bitte auch das zusätzliche Leerzeichen vor dem Prozentzeichen. Das ist im Message-String auch enthalten!
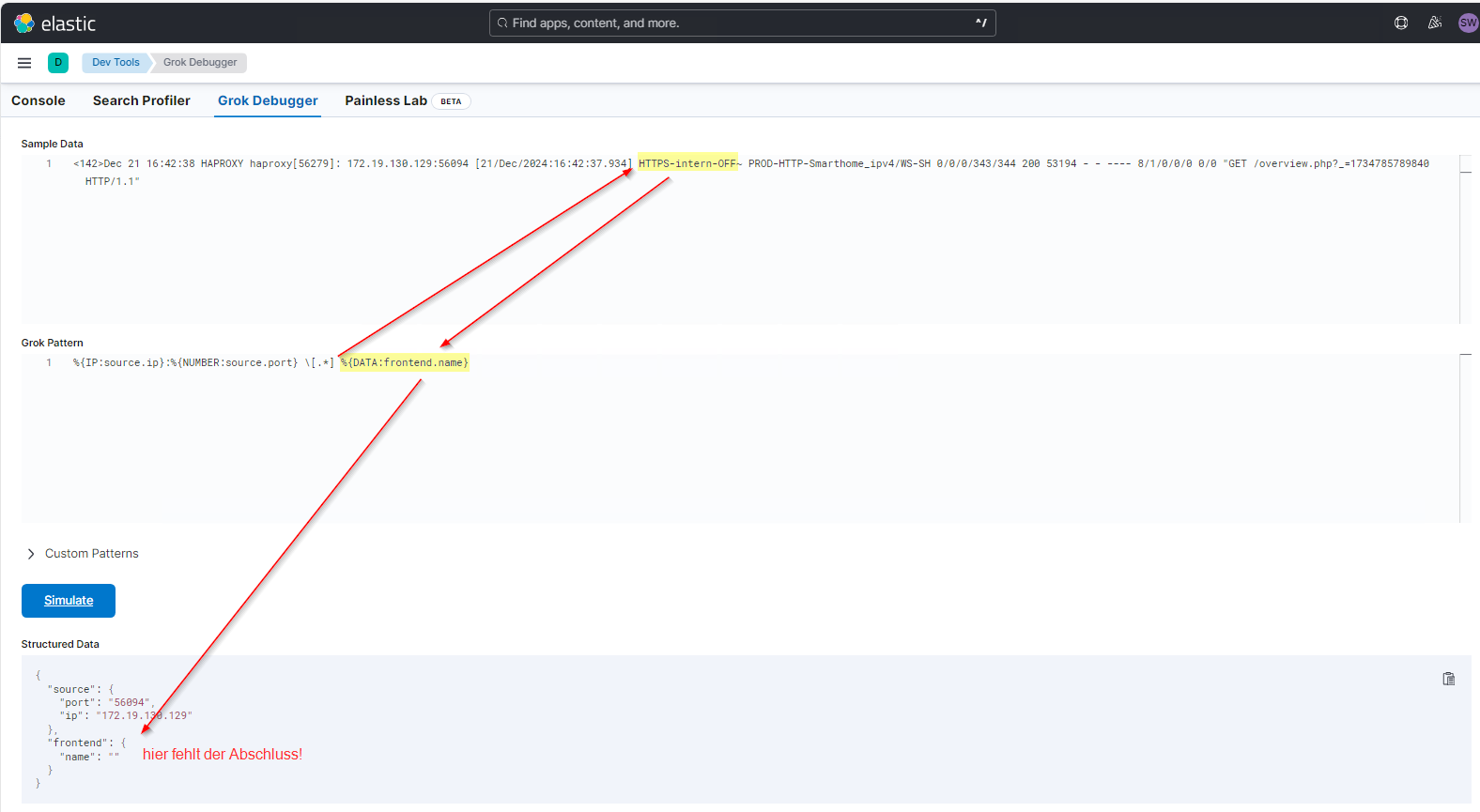
Nehme ich das Tildezeichen danach mit dazu, dann wird der Text damit abgeschlossen und kann extrahiert werden:
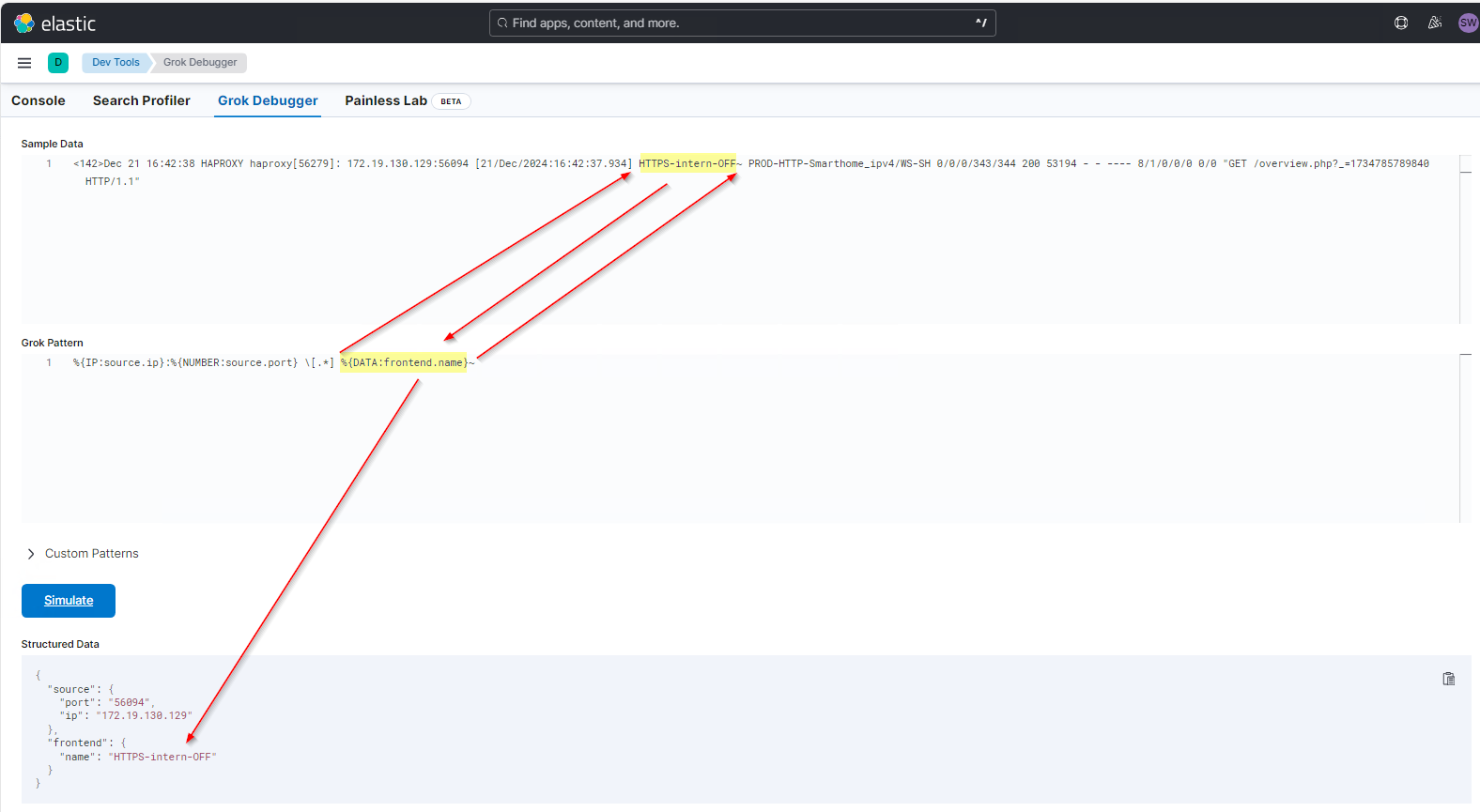
Und so geht es immer weiter, bis ich alle Properties entnommen habe. Die Daten gruppiere ich mir durch die Punktnotation im Property-Name sinnvoll. So stehen sie später auch schön zusammen. Im Bild zeigen die Pfeile die Trennzeichen zwischen den Properties an:
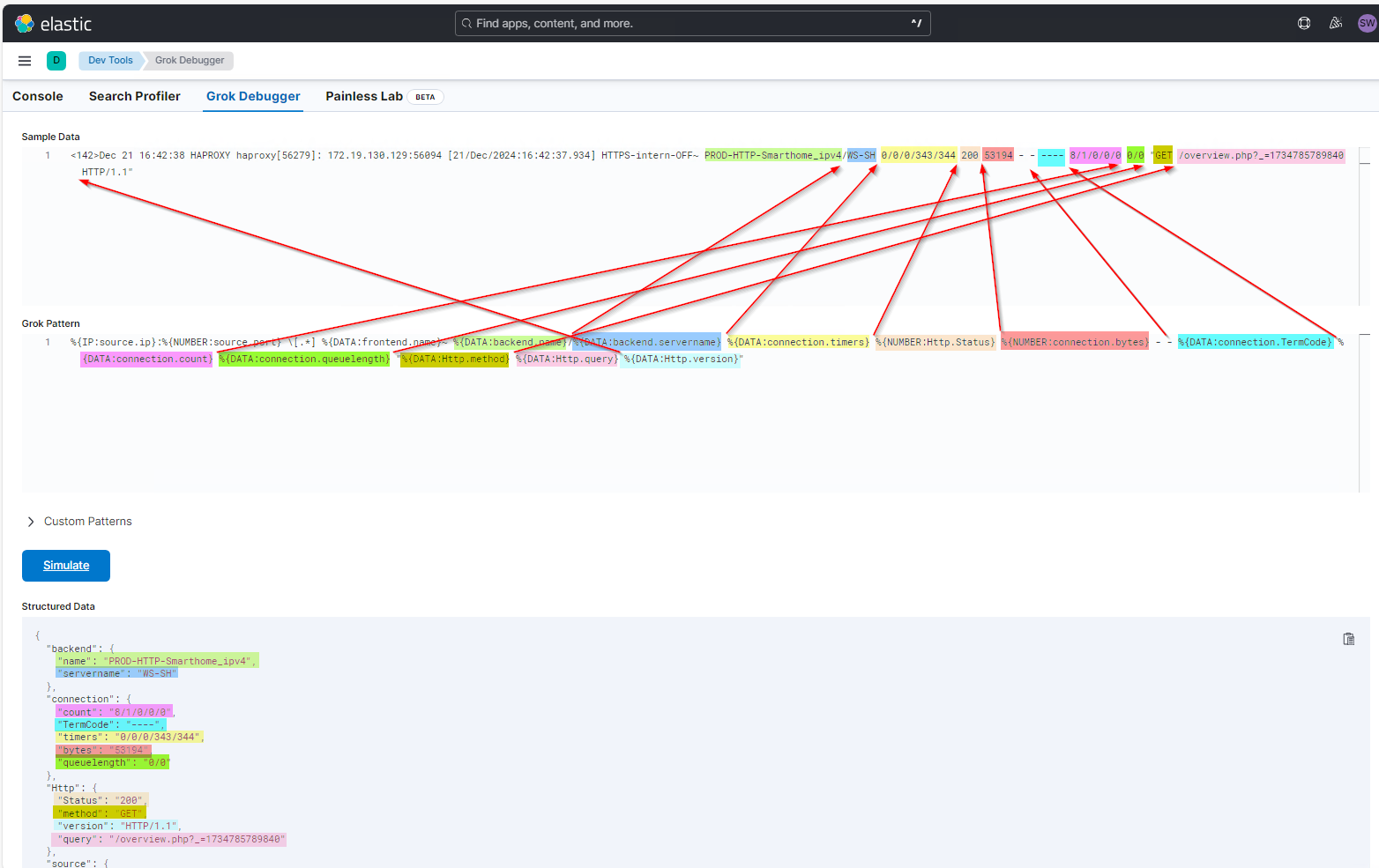
Das ist also mein erster Grok Pattern:
%{IP:source.ip}:%{NUMBER:source.port} [.*] %{DATA:frontend.name}~ %{DATA:backend.name}/%{DATA:backend.servername} %{DATA:connection.timers} %{NUMBER:Http.Status} %{NUMBER:connection.bytes} – – %{DATA:connection.TermCode} %{DATA:connection.count} %{DATA:connection.queuelength} „%{DATA:Http.method} %{DATA:Http.query} %{DATA:Http.version}“
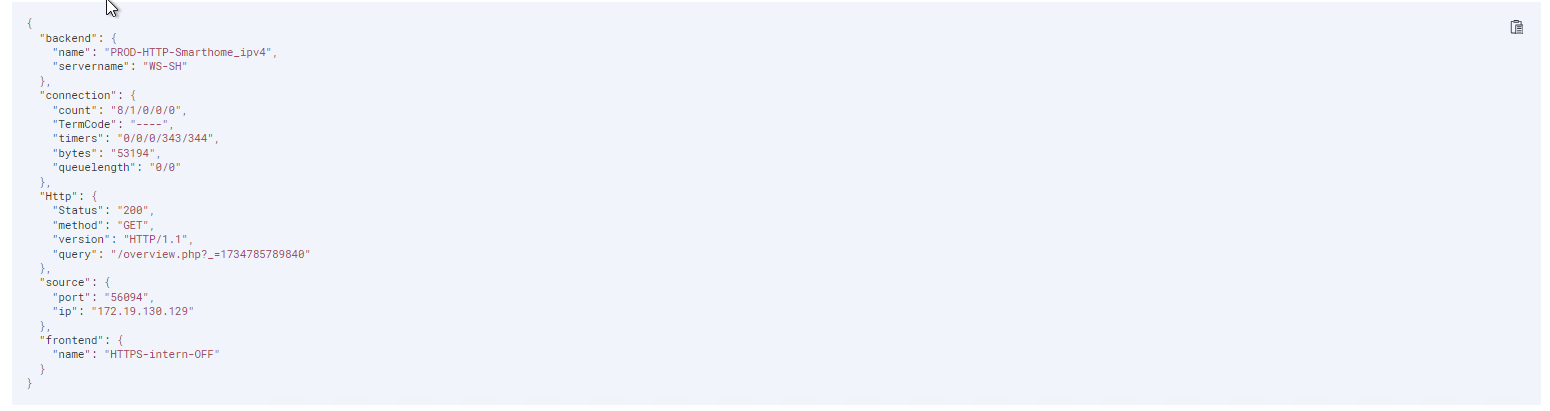
Und das ist das vorläufige Ergebnis im Grok Developer:
Einbau des Grok Patterns im Logstash
Nun muss ich den neuen Pattern in meinem Logstash einbauen. Für die eingehende Verbindung auf UDP:10001 habe ich dort eine Konfigurationsdatei angelegt und deren Filter leer gelassen. Diese Datei muss ich nun bearbeiten. Also verbinde ich mit via SSH mit meinem ELK-Server. Die Datei habe ich zwischenzeitlich umbenannt, damit ich deren Verwendung besser zuordnen kann:

Ich editiere die Datei mit nano. Das ist der aktuelle Inhalt. Es werden alle Messages via UDP:10001 angenommen und als Message-Strings an ElasticSearch weitergeleitet:
input {
udp {
host => "192.168.100.32"
port => 10001
}
}
filter {}
output {
elasticsearch {
hosts => ["https://ws-siem.ws.its:9200"]
api_key => "####################:################-#####"
data_stream => true
ssl => true
cacert => "/etc/ssl/cert/siem9200.crt"
}
}In die Filtersektion gehört nun der Grok Pattern mit rein. Hier nutze ich ein match, um den Filter und das dazugehörige Parsing anzugeben. Sollte der Filter passen, dann werden mit add_field noch 2 weitere Properties erzeugt. Und mit add_tag tagge ich jedes Event, damit ich sie später leichter wiederfinden und filtern kann. Vereinfacht schaut das so aus:
input {
udp {
host => "192.168.100.32"
port => 10001
}
}
filter {
grok {
match => { "message" => '<Grok Pattern>' }
}
}
output {
elasticsearch {
hosts => ["https://ws-siem.ws.its:9200"]
api_key => "####################:################-#####"
data_stream => true
ssl => true
cacert => "/etc/ssl/cert/siem9200.crt"
}
}Und ausgefüllt ergibt sich dieser Text:
input {
udp {
host => "192.168.100.32"
port => 10001
}
}
filter {
grok {
match => { "message" => '%{IP:source.ip}:%{NUMBER:source.port} \[.*] %{DATA:frontend.name}~ %{DATA:backend.name}/%{DATA:backend.servername} %{DATA:connection.timers} %{NUMBER:Http.Status} %{NUMBER:connection.bytes} - - %{DATA:connection.TermCode} %{DATA:connection.count} %{DATA:connection.queuelength} "%{DATA:Http.method} %{DATA:Http.query} %{DATA:Http.version}"' }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
add_tag => [ "haproxy” ]
}
}
output {
elasticsearch {
hosts => ["https://ws-siem.ws.its:9200"]
api_key => "####################:################-#####"
data_stream => true
ssl => true
cacert => "/etc/ssl/cert/siem9200.crt"
}
}Ich speichere die Datei und starten den Service logstash neu. Das dauert einen Moment, wie das Log zeigt:
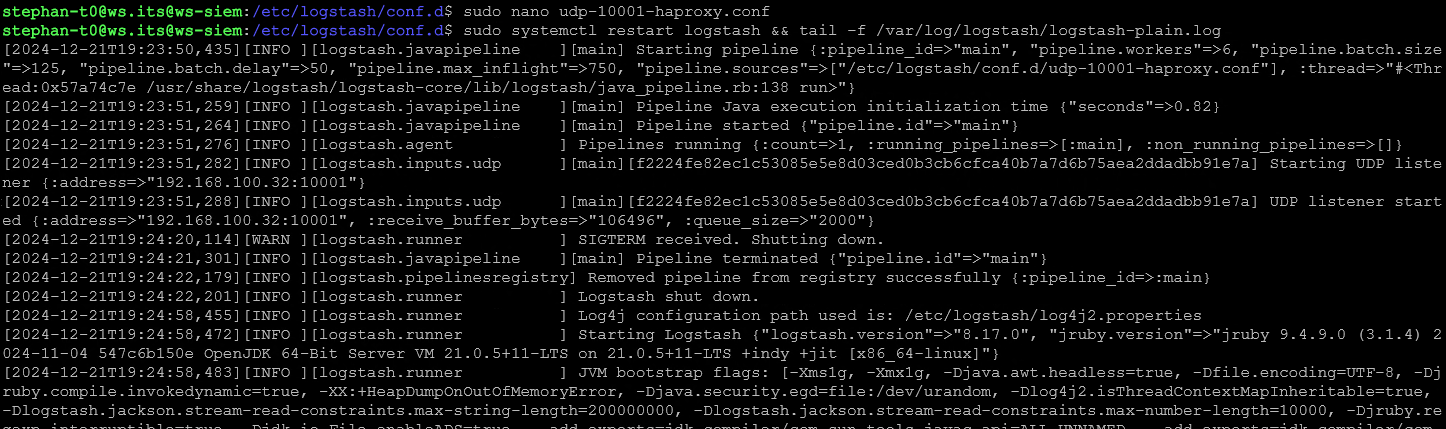
Nun suche ich wieder nach Events im Kibana. Leider werden die Logs nicht korrekt geparst!
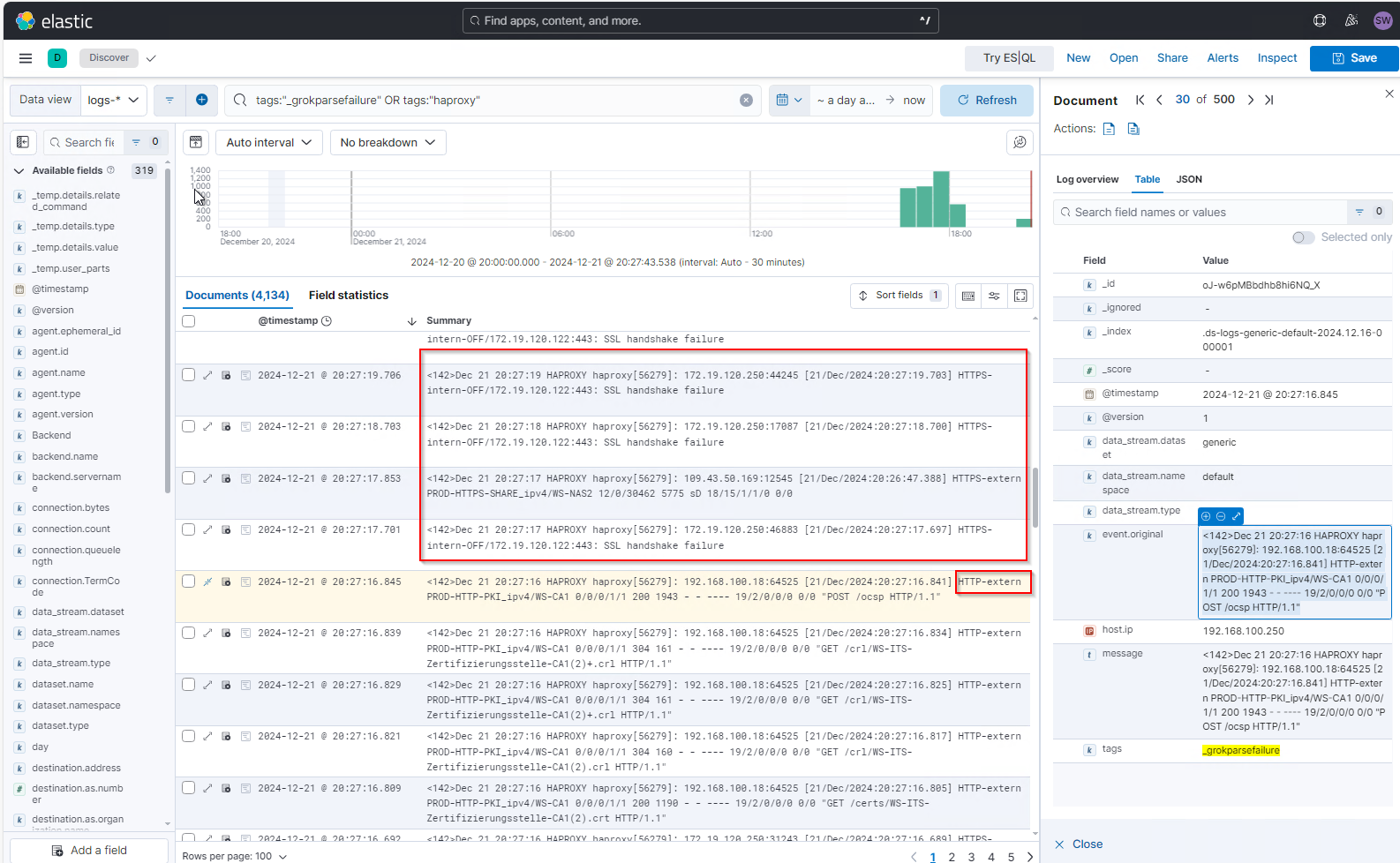
Zum einen gibt es hier noch andere Message-Strings, für die mein Patternfilter nicht matcht. Und zum anderen scheint das Tildezeichen meines Frontends nicht immer mit dabei zu sein – wahrscheinlich nur, wenn der String zu lang wird. Also matcht der Filter auch hier nicht. Daher passe ich meinen Filterstring erneut an und entferne das Tildezeichen nach %{DATA:frontend.name}:
input {
udp {
host => "192.168.100.32"
port => 10001
}
}
filter {
grok {
match => { "message" => '%{IP:source.ip}:%{NUMBER:source.port} \[.*] %{DATA:frontend.name} %{DATA:backend.name}/%{DATA:backend.servername} %{DATA:connection.timers} %{NUMBER:Http.Status} %{NUMBER:connection.bytes} - - %{DATA:connection.TermCode} %{DATA:connection.count} %{DATA:connection.queuelength} "%{DATA:Http.method} %{DATA:Http.query} %{DATA:Http.version}"' }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
add_tag => [ "haproxy” ]
}
}
output {
elasticsearch {
hosts => ["https://ws-siem.ws.its:9200"]
api_key => "####################:################-#####"
data_stream => true
ssl => true
cacert => "/etc/ssl/cert/siem9200.crt"
}
}Dann starte ich meinen Logstash durch und warte auf neue Logs im Kibana. Jetzt schaut es gut aus:
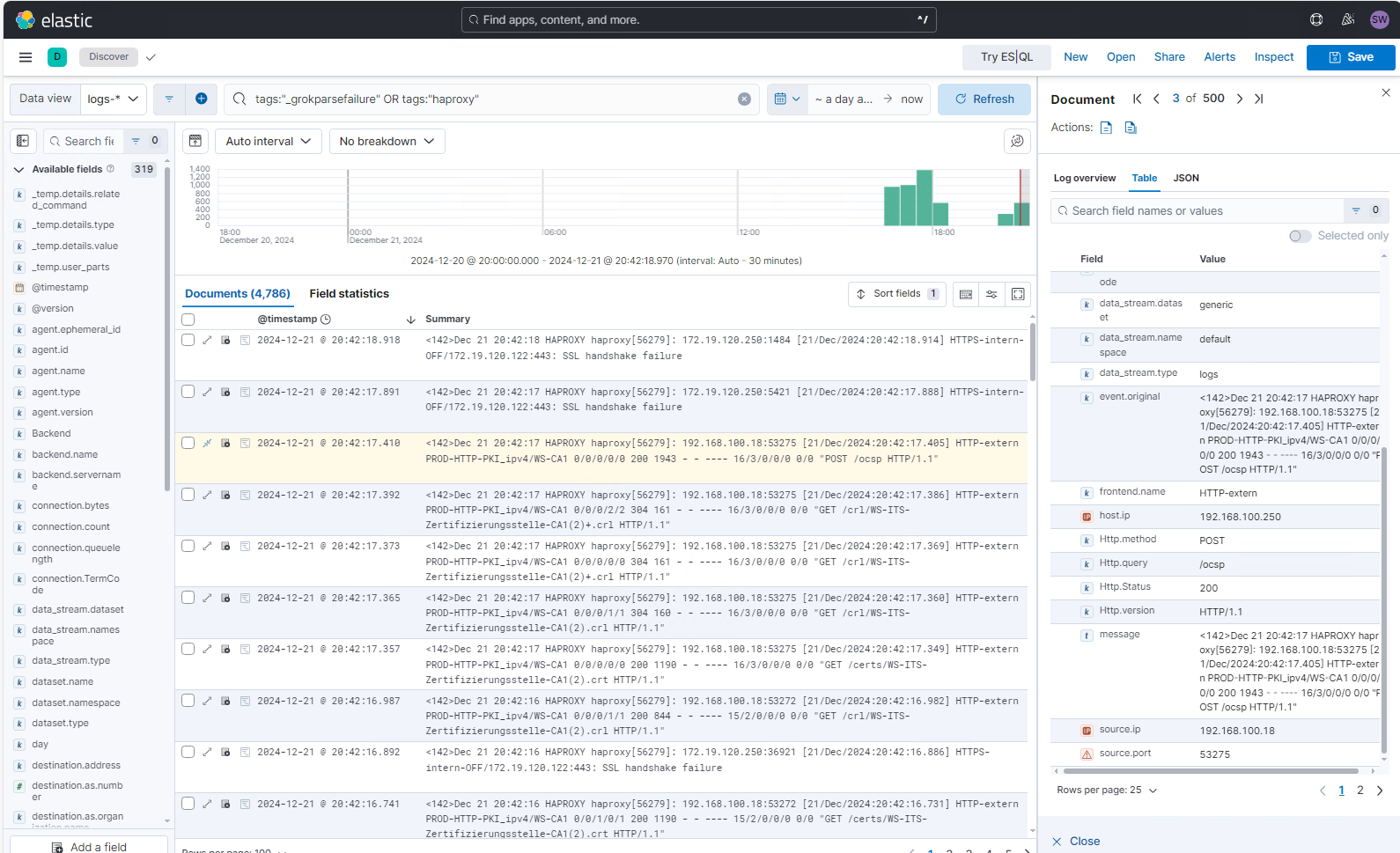
Aufbau weiterer Grok-Patterns
Nun extrahiere ich den 2. Message-String-Typ und baue dafür im Grok Developer einen Pattern. Hier nutze ich für den restlichen Text ein %{GREEDYDATA:connection.message}
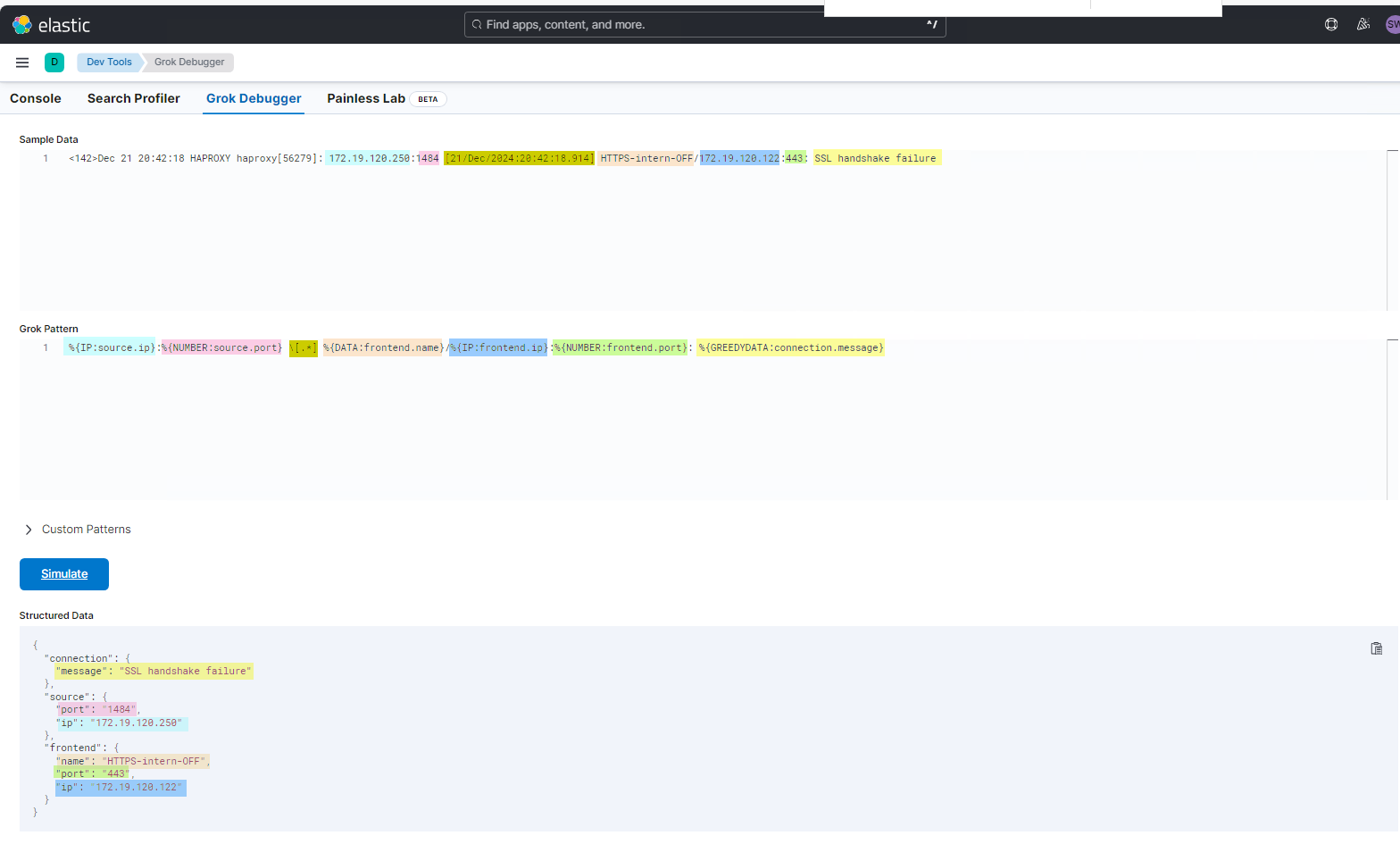
Dann muss der neue Pattern in das Logstash-File eingetragen werden. also gehts zurück zur SSH-Session in den nano-Editor. Wie man erkennen kann, dürfen mehrere Grok-Filter untereinander stehen:
input {
udp {
host => "192.168.100.32"
port => 10001
}
}
filter {
grok {
match => { "message" => '%{IP:source.ip}:%{NUMBER:source.port} \[.*] %{DATA:frontend.name} %{DATA:backend.name}/%{DATA:backend.servername} %{DATA:connection.timers} %{NUMBER:Http.Status} %{NUMBER:connection.bytes} - - %{DATA:connection.TermCode} %{DATA:connection.count} %{DATA:connection.queuelength} "%{DATA:Http.method} %{DATA:Http.query} %{DATA:Http.version}"' }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
add_tag => [ "haproxy” ]
}
grok {
match => { "message" => '%{IP:source.ip}:%{NUMBER:source.port} \[.*] %{DATA:frontend.name}/%{IP:frontend.ip}:%{NUMBER:frontend.port}: %{GREEDYDATA:connection.message}' }
add_tag => [ "haproxy” ]
}
}
output {
elasticsearch {
hosts => ["https://ws-siem.ws.its:9200"]
api_key => "####################:################-#####"
data_stream => true
ssl => true
cacert => "/etc/ssl/cert/siem9200.crt"
}
}Ich starte Logstash neu. Dieses mal wirft das Log aber einen Fehler aus:
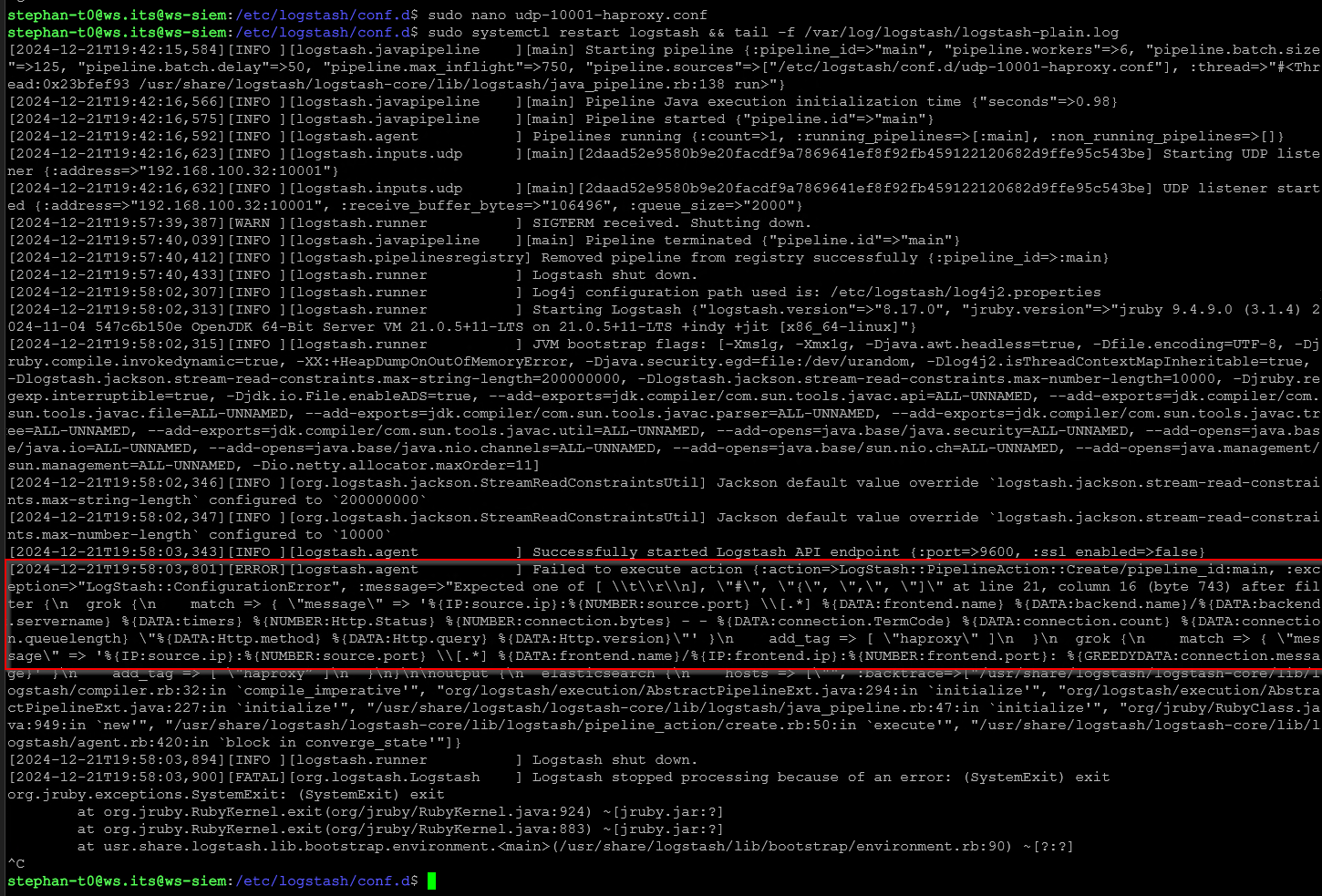
Ich kontrolliere also noch einmal meine Konfigurationsdatei. Oft passiert so etwas wohl, wenn man die Strings in eine SSH-Session aus Browsern oder aus notepad++ über die Zwischenablage kopiert. Dann werden ggf. Sonderzeichen oder versteckte Steuerzeichen mit kopiert. Ich setze den String also im nano noch einmal direkt zusammen und teste erneut. Jetzt werden die Properties erkannt. Aber zusätzlich finde ich das Tag _grokparsefailure…
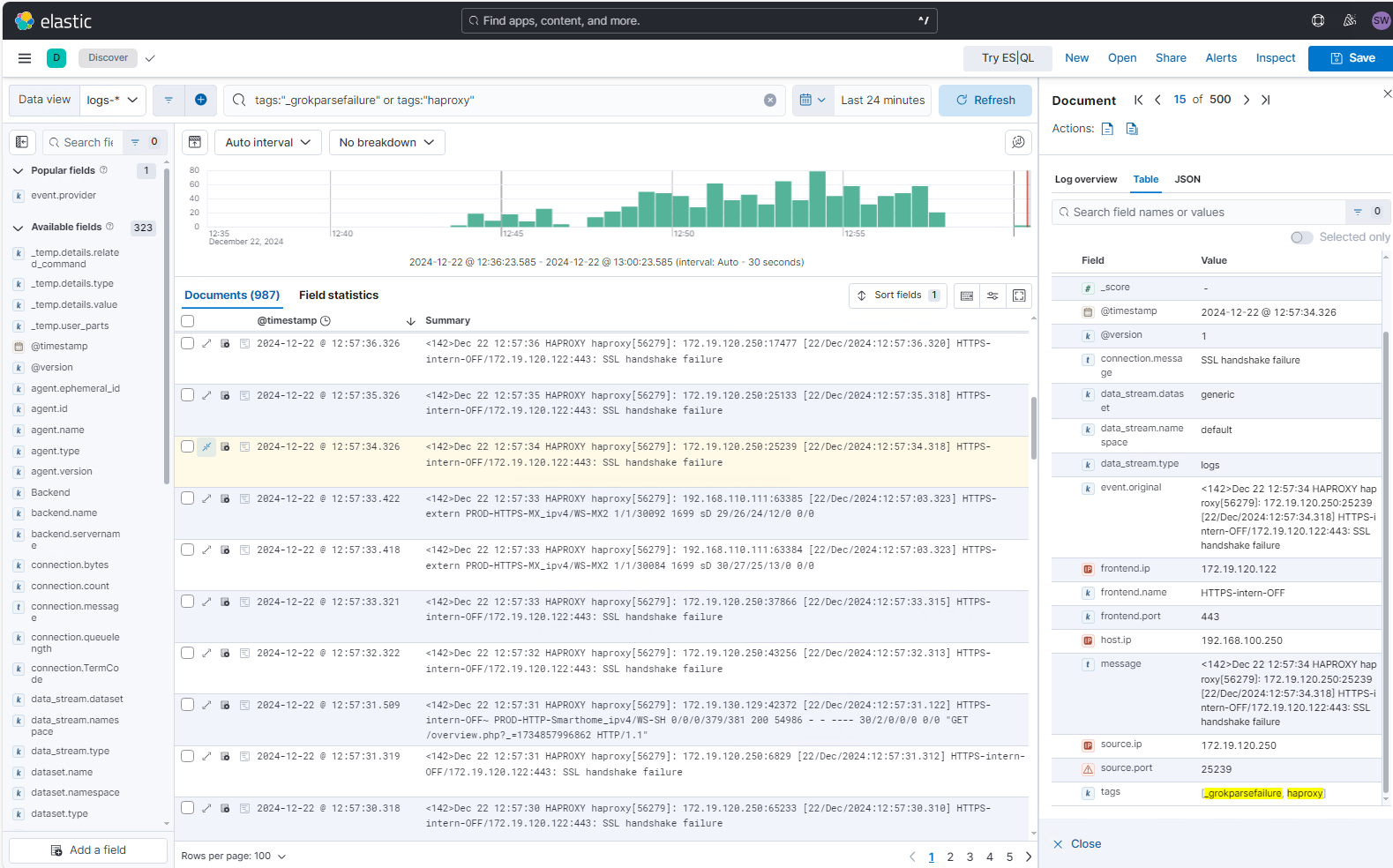
Nach einer Recherche im Netz habe ich herausgefunden, dass meine Vorgehensweise mit den multiplen Grok-Patterns das Problem verursacht. Offenbar werden so alle Filter in einer Sequenz nacheinander angewendet. Ich muss eine andere Logik in meiner config-File finden. Nach einigen Versuchen habe ich diese hier gefunden. Die unterschiedlichen Grok-Patterns werden kommagetrennt in einem Array (eckige Klammer) der Message zugewiesen. Das zusätzliche break_on_match weist Logstash an, beim ersten Treffer alle weiteren Patterns zu ignorieren:
input {
udp {
host => "192.168.100.32"
port => 10001
}
}
filter {
grok {
match => {
"message" => [
'%{IP:source.ip}:%{NUMBER:source.port} \[.*] %{DATA:frontend.name} %{DATA:backend.name}/%{DATA:backend.servername} %{DATA:timers} %{NUMBER:Http.Status} %{NUMBER:connection.bytes} - - %{DATA:connection.TermCode} %{DATA:connection.count} %{DATA:connection.queuelength} "%{DATA:Http.method} %{DATA:Http.query} %{DATA:Http.version}"',
'%{IP:source.ip}:%{NUMBER:source.port} \[.*] %{DATA:frontend.name}/%{IP:frontend.ip}:%{NUMBER:frontend.port}: %{GREEDYDATA:connection.message}'
]
}
add_tag => [ "haproxy" ]
break_on_match => true
}
}
output {
elasticsearch {
hosts => ["https://ws-siem.ws.its:9200"]
api_key => "####################:################-#####"
data_stream => true
ssl => true
cacert => "/etc/ssl/cert/siem9200.crt"
}
}
Damit sind die grok-Fehler verschwunden 🙂
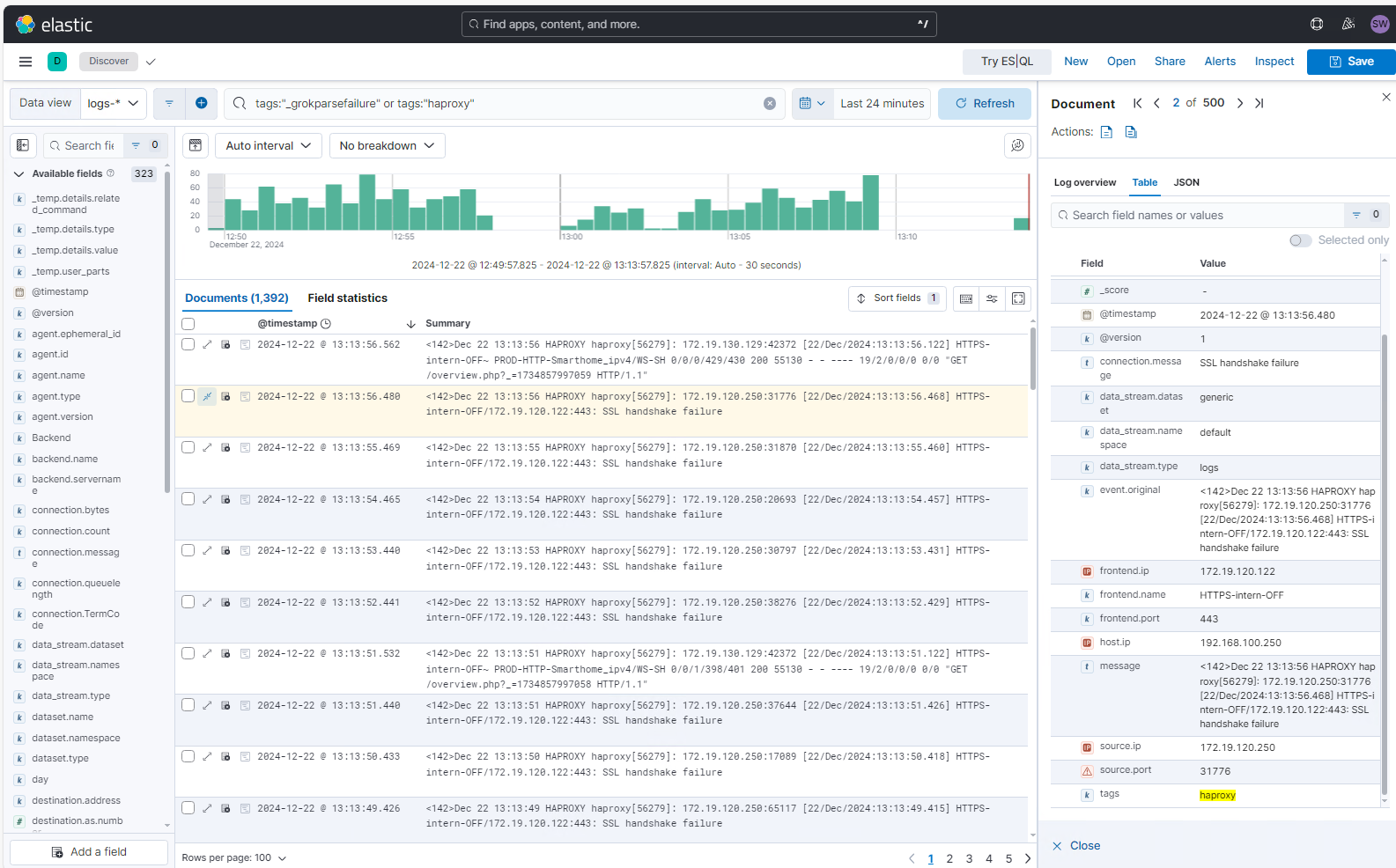
Uns so suche ich weiter nach Events, bei denen das Parsing noch nicht passt und erweitere meinen Grok-Pattern:
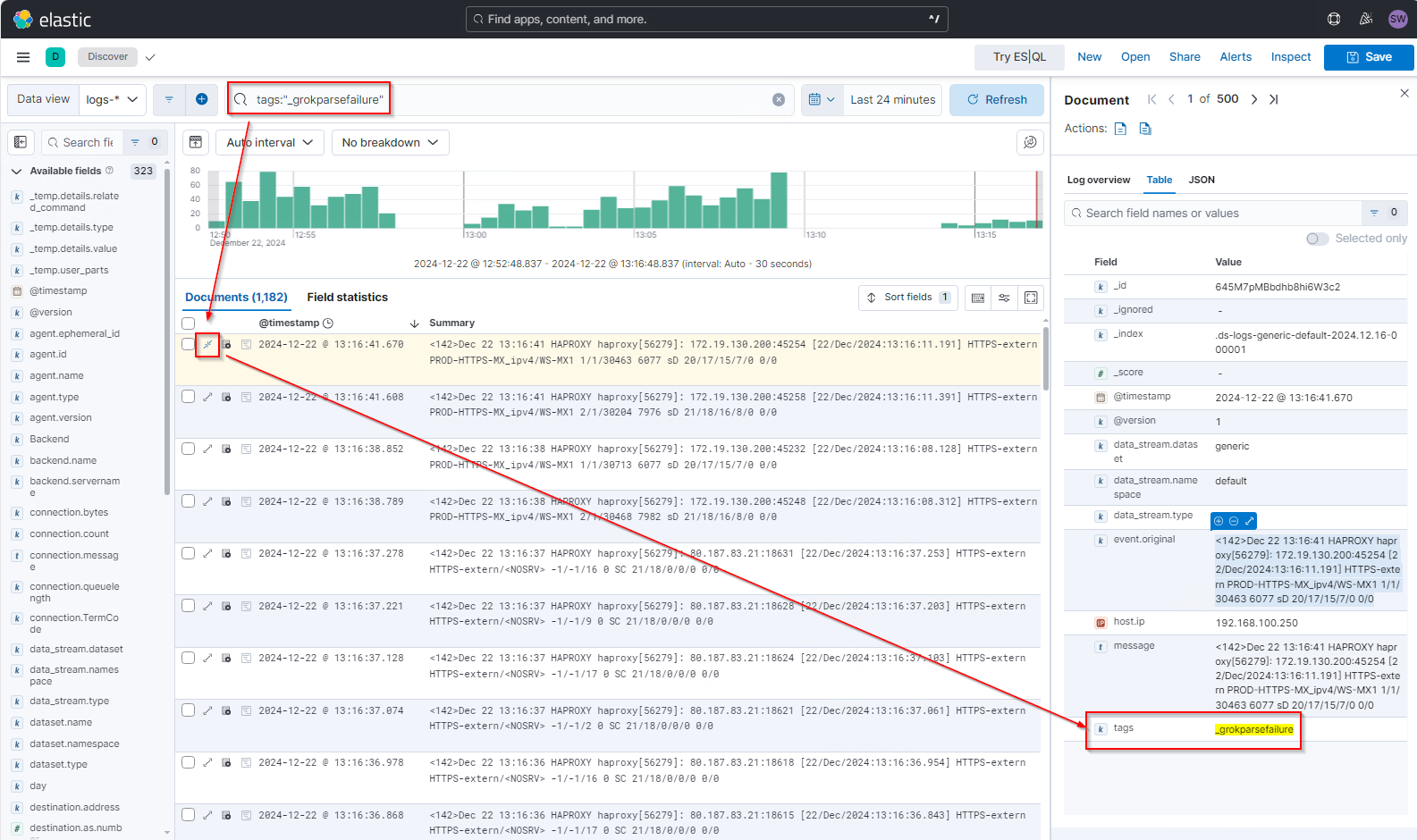
So komme ich nun zu dieser finalen Logstash-config:
input {
udp {
host => "192.168.100.32"
port => 10001
}
}
filter {
grok {
match => {
"message" => [
'%{IP:source.ip}:%{NUMBER:source.port} \[.*] %{DATA:frontend.name} %{DATA:backend.name}/%{DATA:backend.servername} %{DATA:timers} %{NUMBER:Http.Status} %{NUMBER:connection.bytes} - - %{DATA:connection.TermCode} %{DATA:connection.count} %{DATA:connection.queuelength} "%{DATA:Http.method} %{DATA:Http.query} %{DATA:Http.version}"',
'%{IP:source.ip}:%{NUMBER:source.port} \[.*] %{DATA:frontend.name}/%{IP:frontend.ip}:%{NUMBER:frontend.port}: %{GREEDYDATA:connection.message}',
'%{IP:source.ip}:%{NUMBER:source.port} \[.*] %{DATA:frontend.name} %{DATA:backend.name}/%{DATA:backend.servername} %{DATA:connection.timers} %{NUMBER:connection.bytes} %{DATA:connection.terminationstate} %{DATA:connection.count} %{GREEDYDATA:connection.queuelength}'
]
}
add_tag => [ "haproxy" ]
break_on_match => true
}
}
output {
elasticsearch {
hosts => ["https://ws-siem.ws.its:9200"]
api_key => "####################:################-#####"
data_stream => true
ssl => true
cacert => "/etc/ssl/cert/siem9200.crt"
}
}Aufbau einer Search
Final erstelle ich nun noch eine Search, mit der ich schnell auf die Daten zugreifen kann und die relevanten Properties tabellarisch gleich mit angezeigt werden:
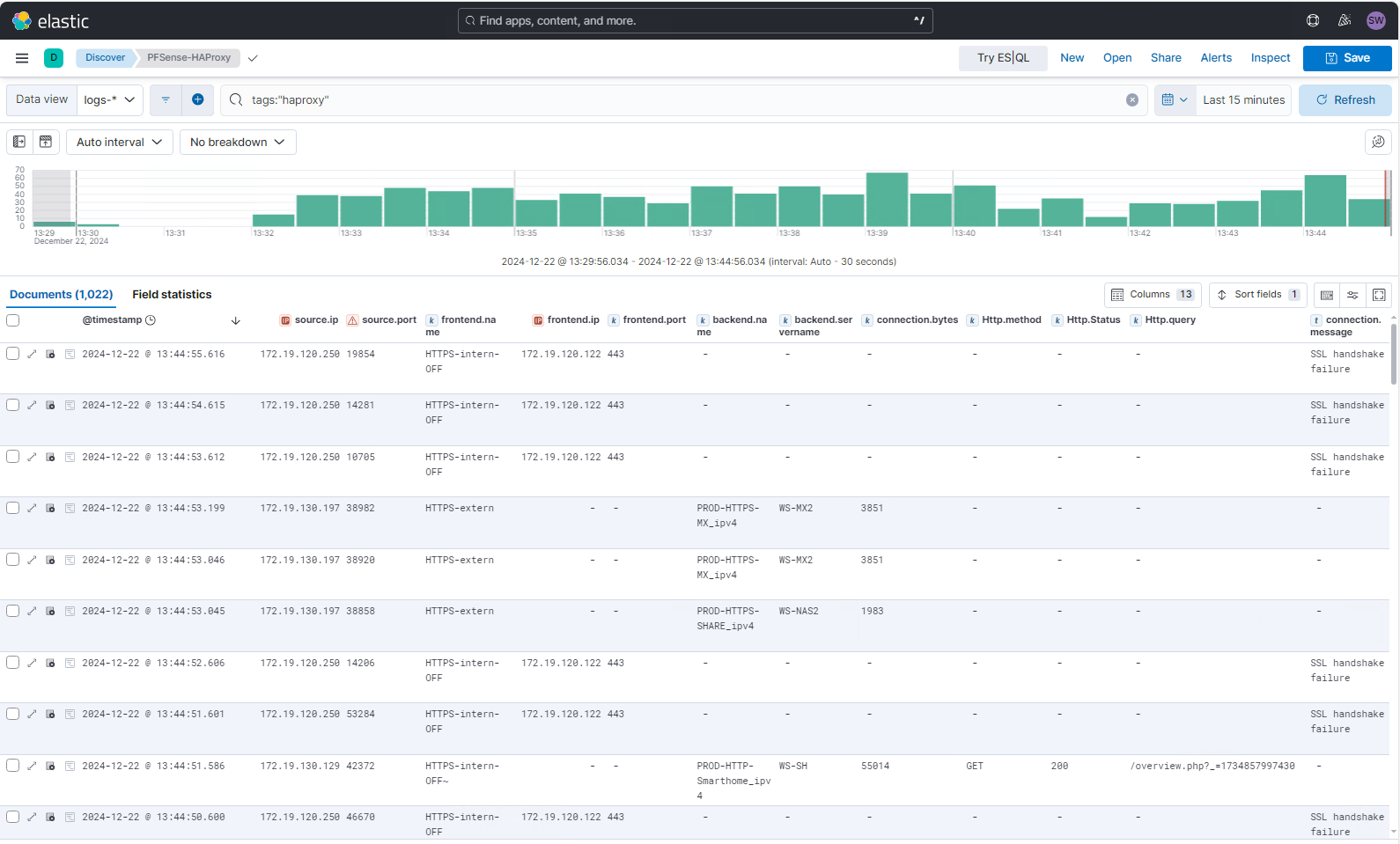
Zusammenfassung
Das war wieder ein komplexeres Thema. bei Grok gibt es vieles zu beachten und Versuche dauern durch den Neustart vom Logstash etwas. Aber insgesamt bin ich nun froh, dass ich 2 weitere Ziele erreicht habe:
- Ich habe meine detaillierten HAProxy-Logfiles endlich im ELK
- Mit dem Logstash und Grok kann ich nun auch Events selber parsen
Meine Logstash-Configfiles könnt ihr euch aus meinem Gitlab herunterladen: https://gitlab.ws-its.de/stephan/elasticsiem
Also kann es mit dem nächsten Thema weiter gehen 🙂 Weitere Artikel findet ihr in meiner Serie „Bereitstellung eines Elastic SIEM„.
Stay tuned