
Inhaltsverzeichnis
Einleitung
Mein Datenvolumen im ElasticSearch wächst immer weiter an. Ich habe mittlerweile mehrfach neuen Speicher hinzufügen müssen. Aber nun ist Schluss damit: ich will die Ursache finden und lösen. In diesem Beitrag zeige ich, wie ich eine unnötige Menge an Events identifiziere und diese gezielt mit dem processor drop_events herausfiltere.
Der Artikel gehört zu meiner Serie „Bereitstellung eines Elastic SIEM„.
Das Problem
Analyse im Elastic
Mein System belegt schon über 400GB. Das kann man schön im Stack Monitoring sehen:
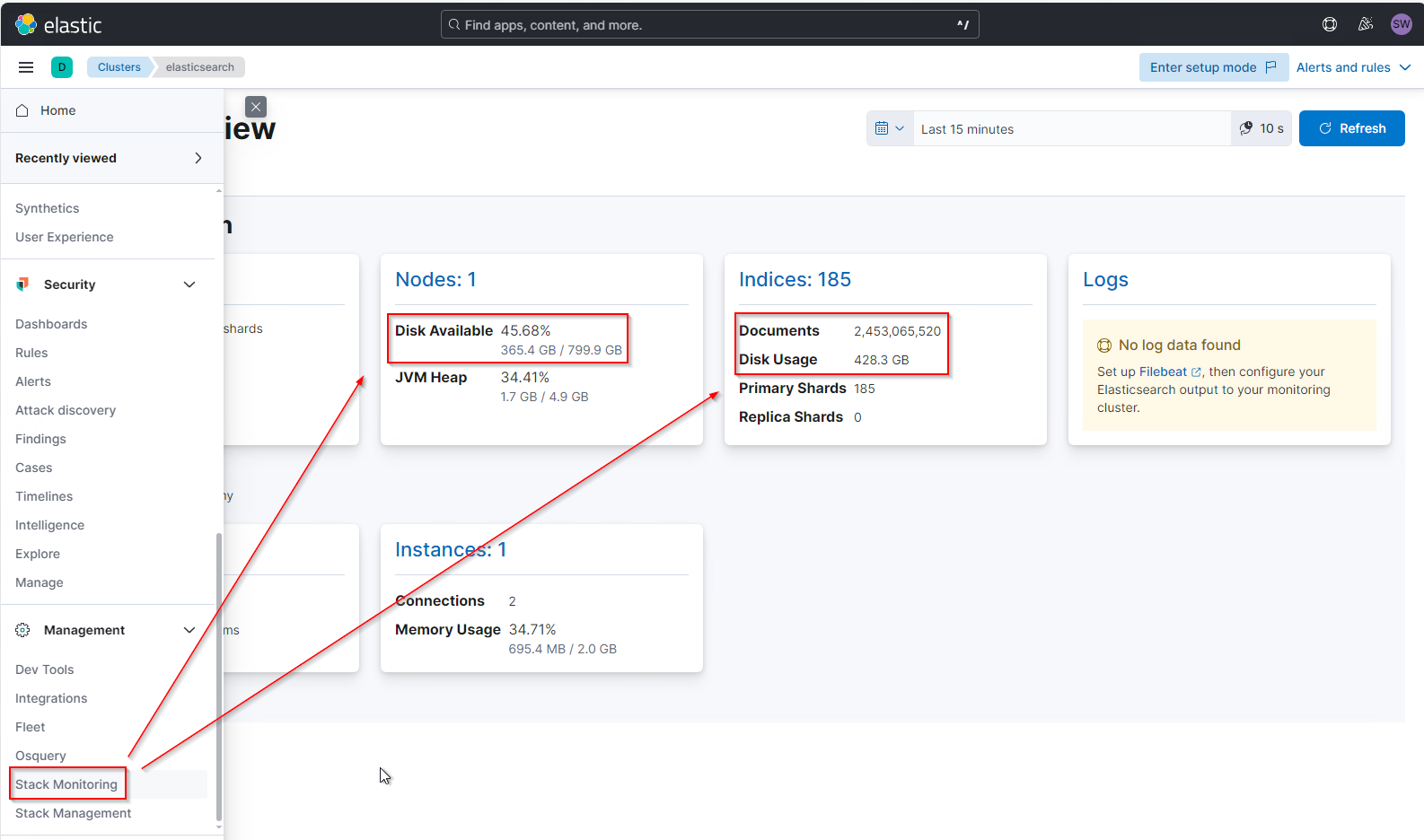
Ich habe aber nur 32 aktive Agents angeschlossen! Das Volumen passt gefühlt nicht zur Anzahl der Systeme. Hier muss irgendwo eine Fehlkonfiguration vorliegen, die meine Platten mit unnötigen Daten füllt.
Um einen ersten Überblick zu erhalten, wechsle ich in das Menü Stack-Management\Data-Set-Quality. Hier stelle ich die letzten 24 Stunden als Analysezeitraum ein und sortiere absteigend nach der Loggröße. Das zeigt mir, dass meine gesammelten Windows Security Logs mit Abstand den meisten Platz beanspruchen:
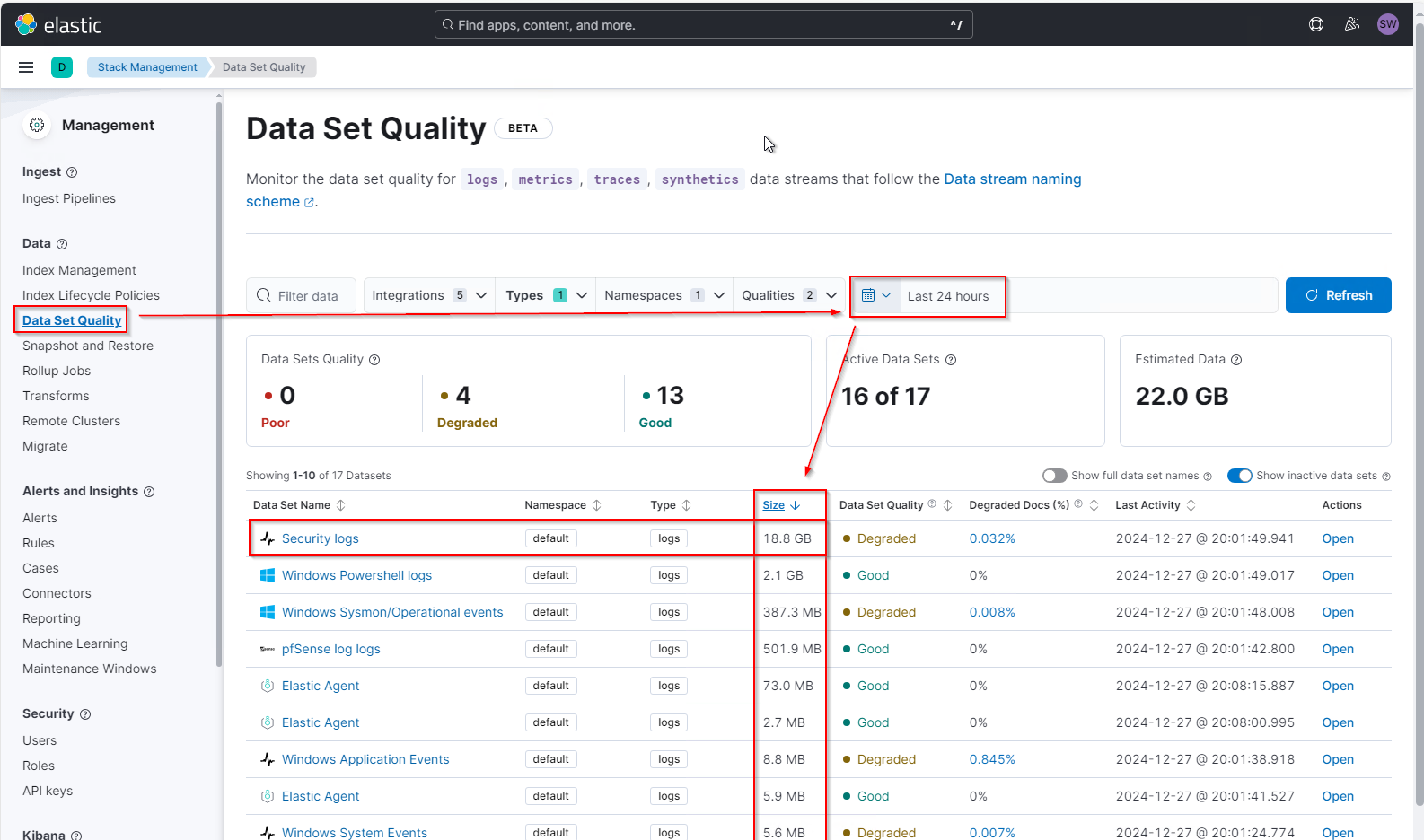
Das spiegelt sich auch in den Indizes wieder. Im Index-Management muss man aber die hidden indices aktivieren und nach der Storage Size absteigend sortieren:
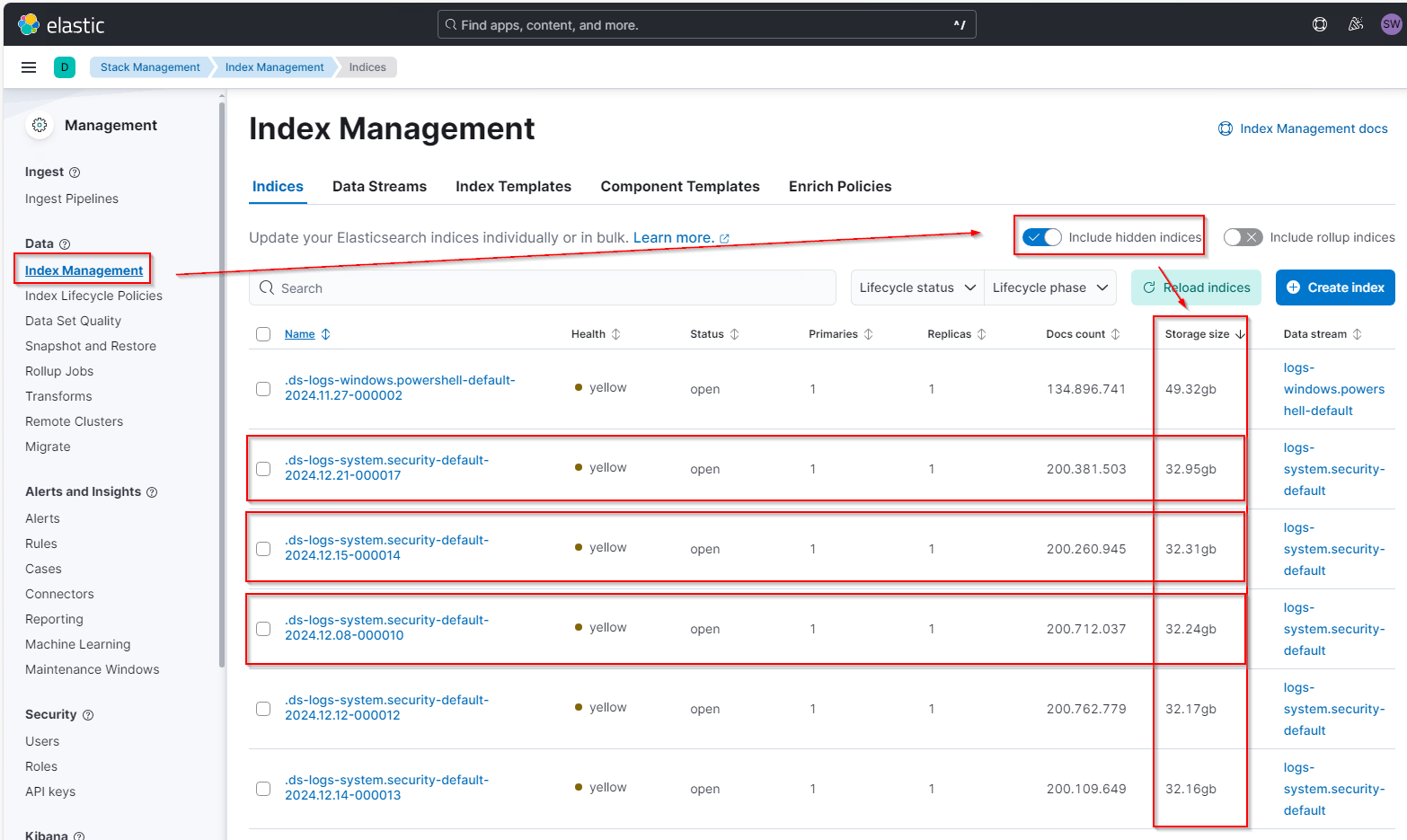
Zum Vergleich: Das hier sind die anderen Logfiles… Man erkennt deutlich den Größenunterschied:
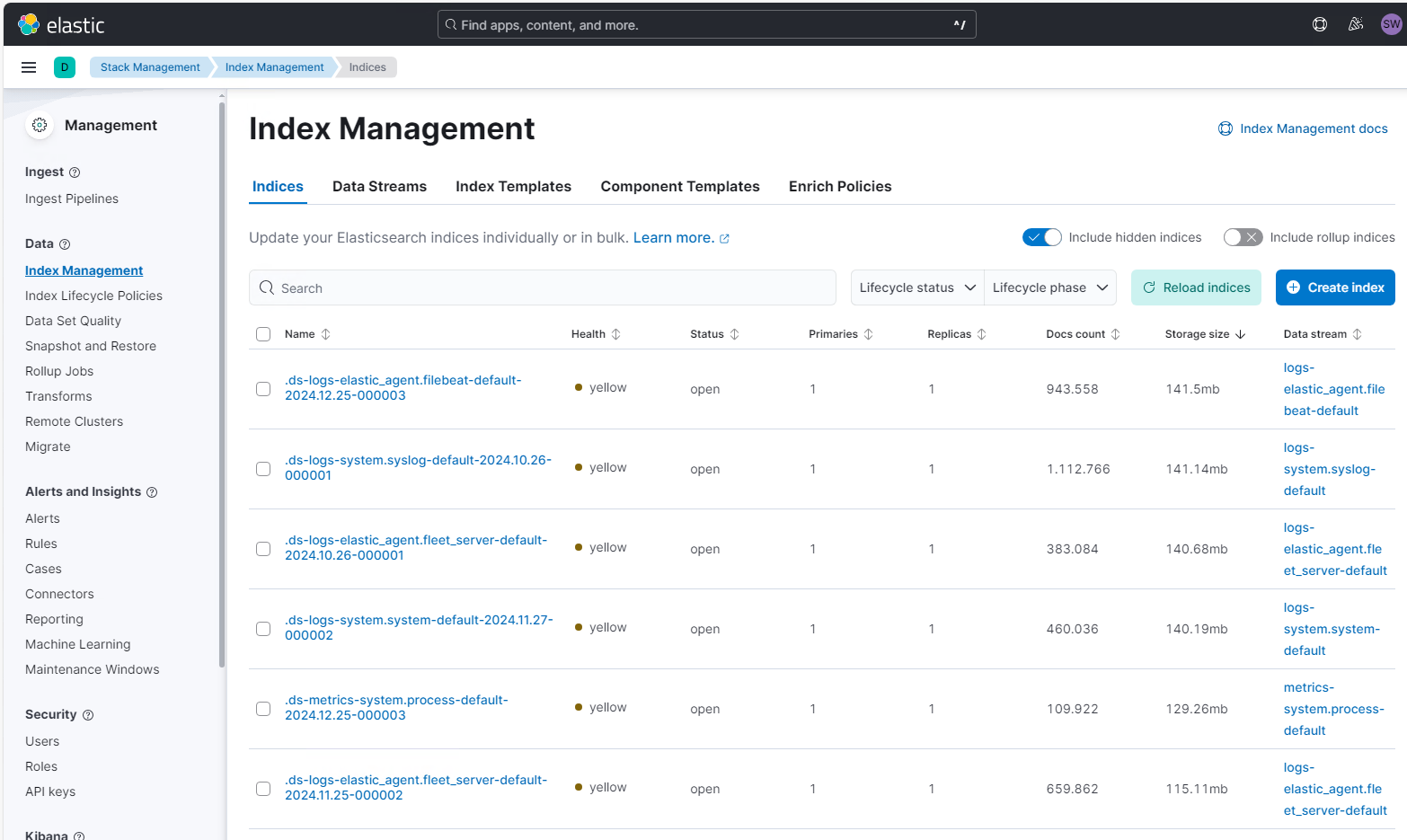
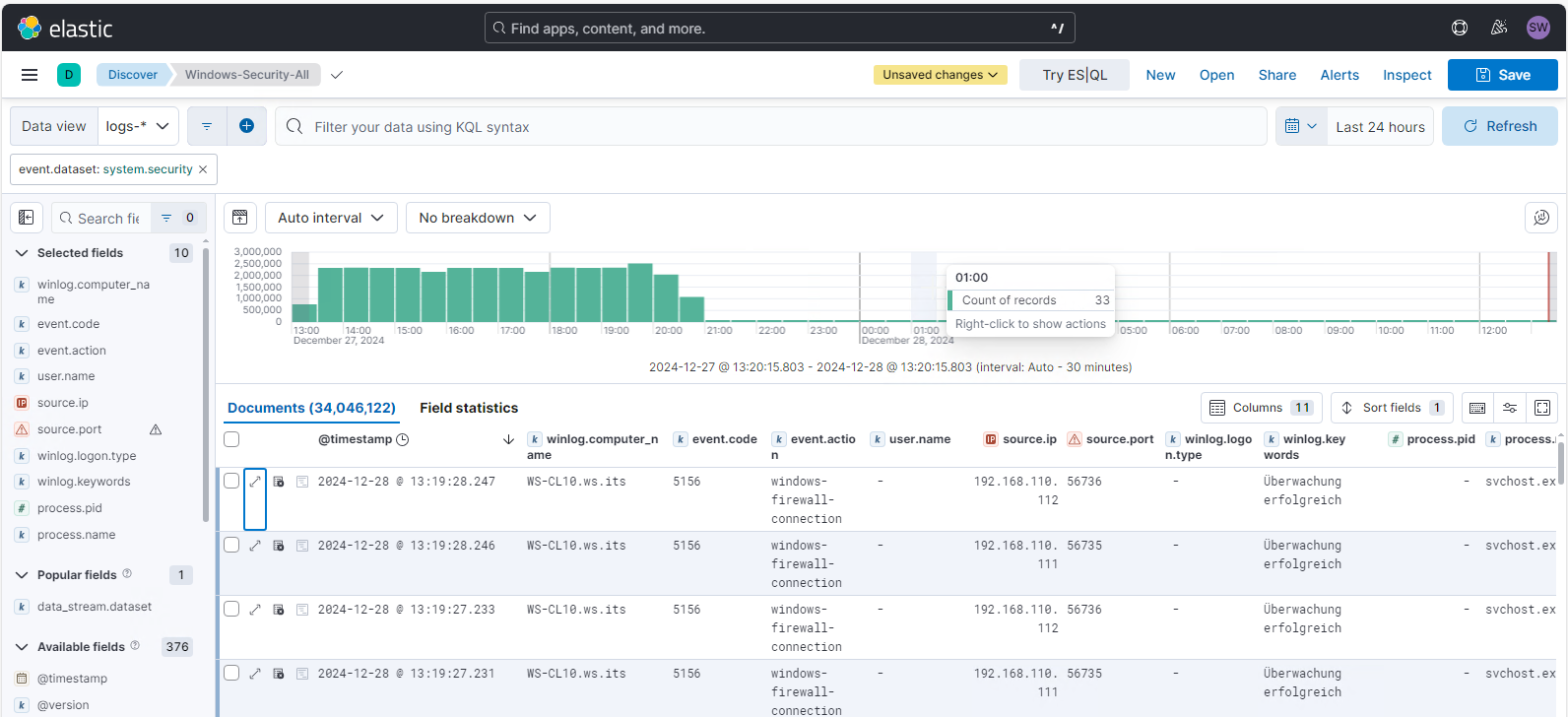
Aber welche Server liefern so viele Daten? Alle Security-Eventlogs aller Windows Systeme werden in einem Index im ElasticSearch gespeichert. Die Verteilung kann ich unter Analytics\Dashboards finden. Da existiert das Dashboard „[Elastic Agent] Overview“. Hier werden im Standard die „most active agents“ gezeigt. Und da sieht man deutlich die Ausreißer:
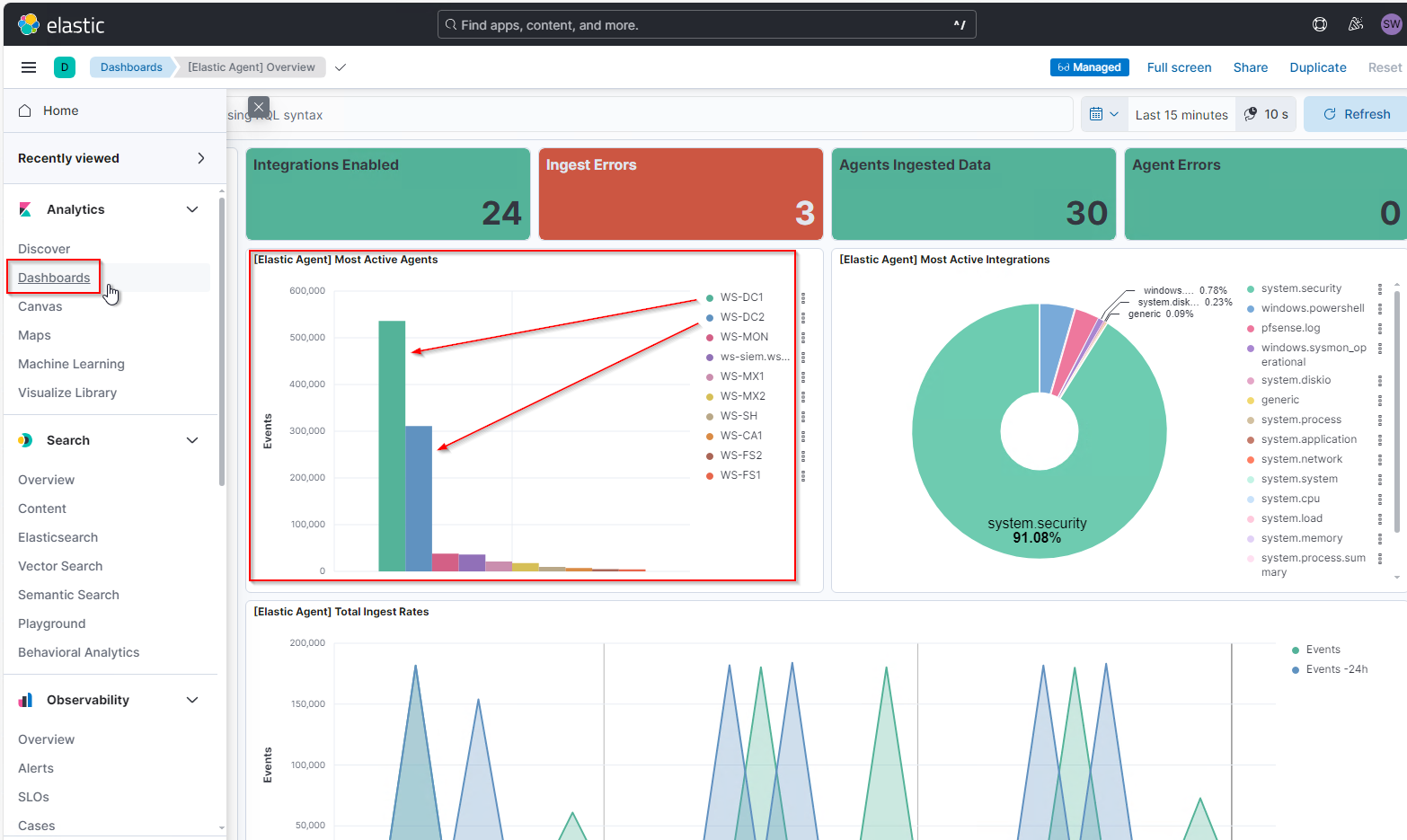
Meine beiden Domain Controller senden ein Vielfaches mehr Logs als alle anderen Systeme zusammen! Da stimmt was nicht. Mit einem Linksklick auf die Säule vom WS-DC1 kann ich dessen Events filtern:
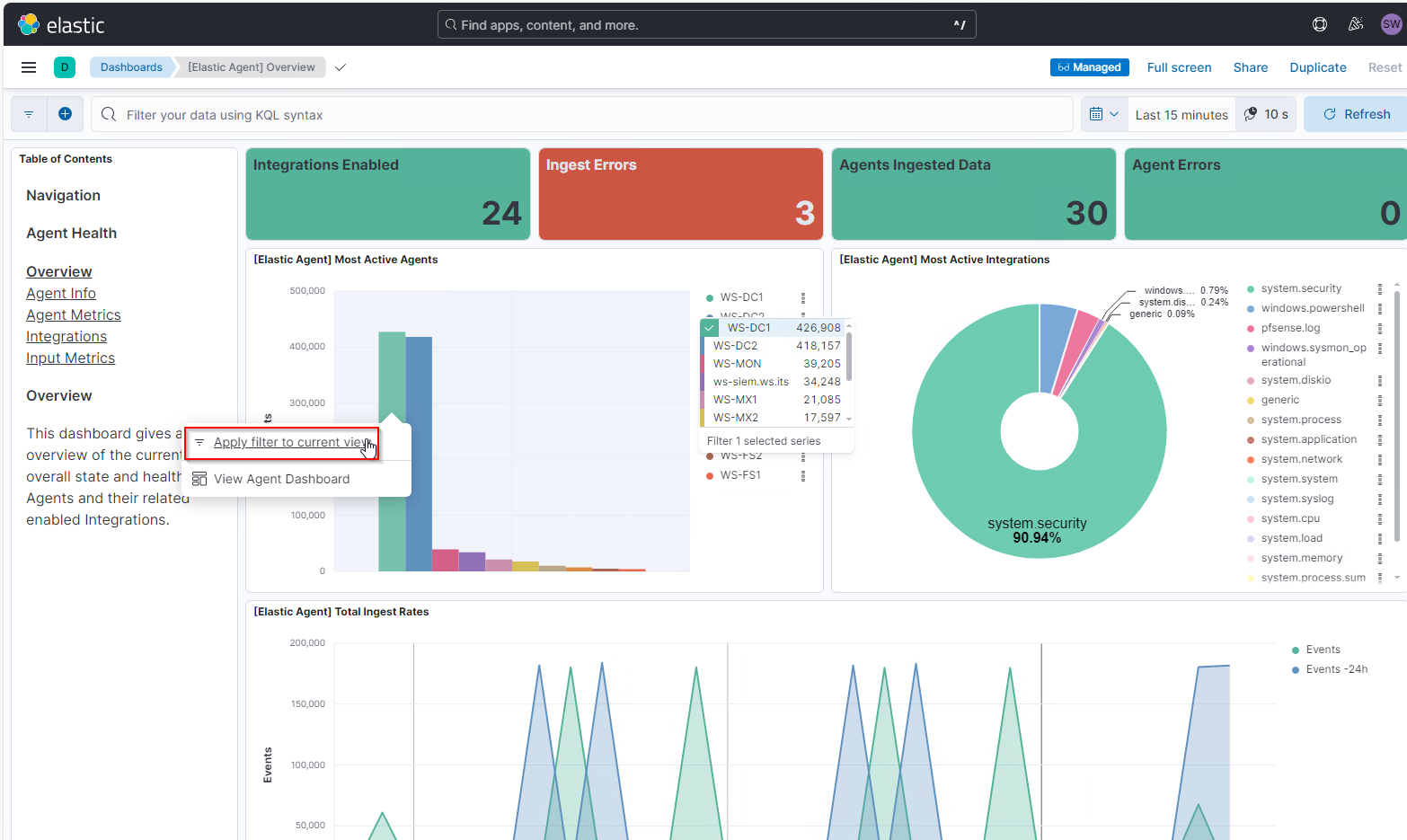
Und auch hier erkenne ich, dass es sich bei diesen knapp 500.000 Events in 15 Minuten (!) zu 98,7% um Security-Log-Events handelt.
Analyse in der Log Source
Ich melde mich auf dem Server an und suche nach einem Muster in der Ereignisanzeige. Hier nutze ich die Zusammenfassung, bei welcher nach den Event IDs und Ereignistypen gruppiert und gezählt wird. Hier sticht nun eine Event ID ganz klar mit 833.791 Events/h heraus:
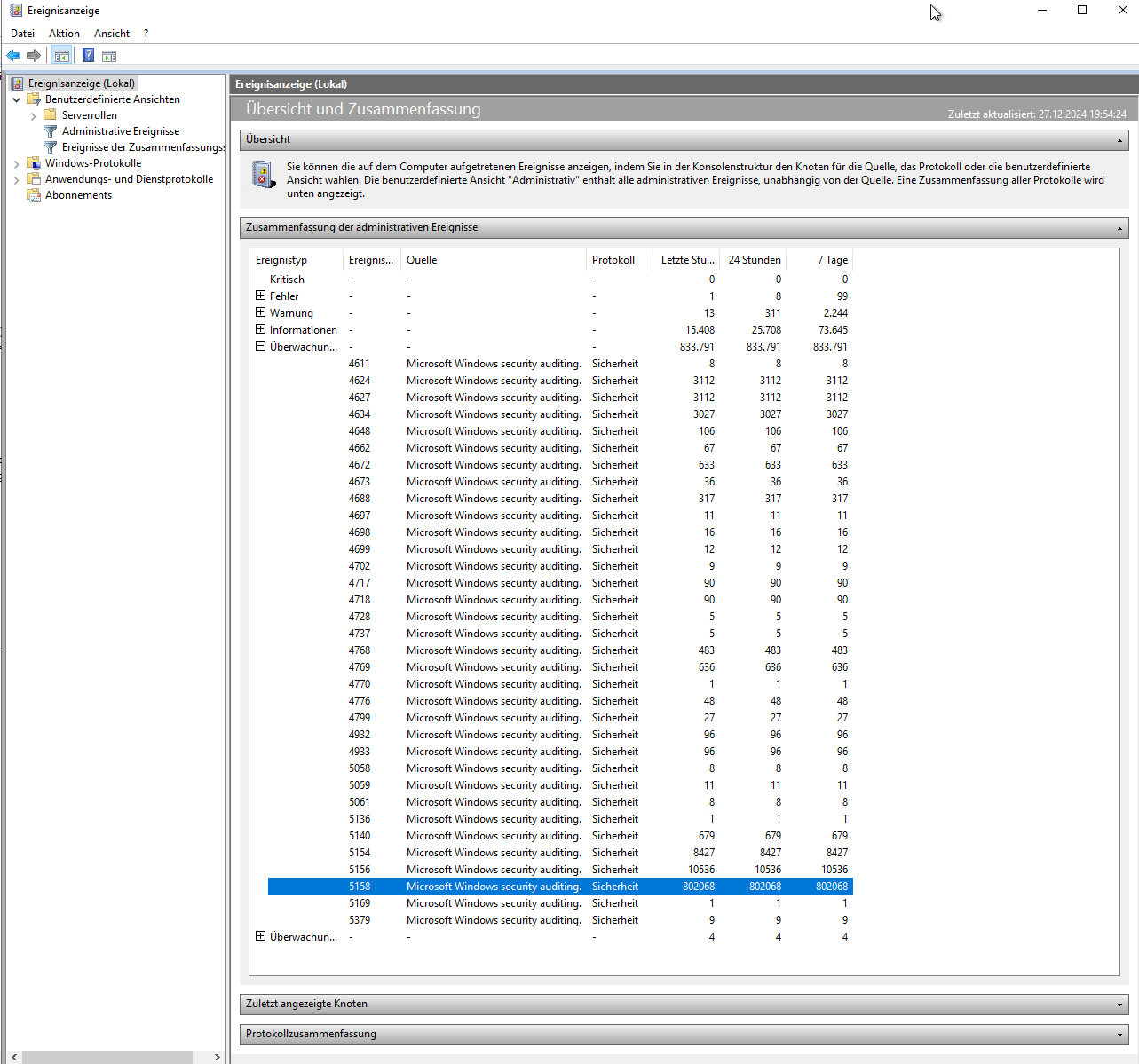
Die Event ID 5158 liefert „The Windows Filtering Platform has permitted a bind to a local port“, also Portbindungs-Informationen (5158(S) The Windows Filtering Platform has permitted a bind to a local port. – Windows 10 | Microsoft Learn):
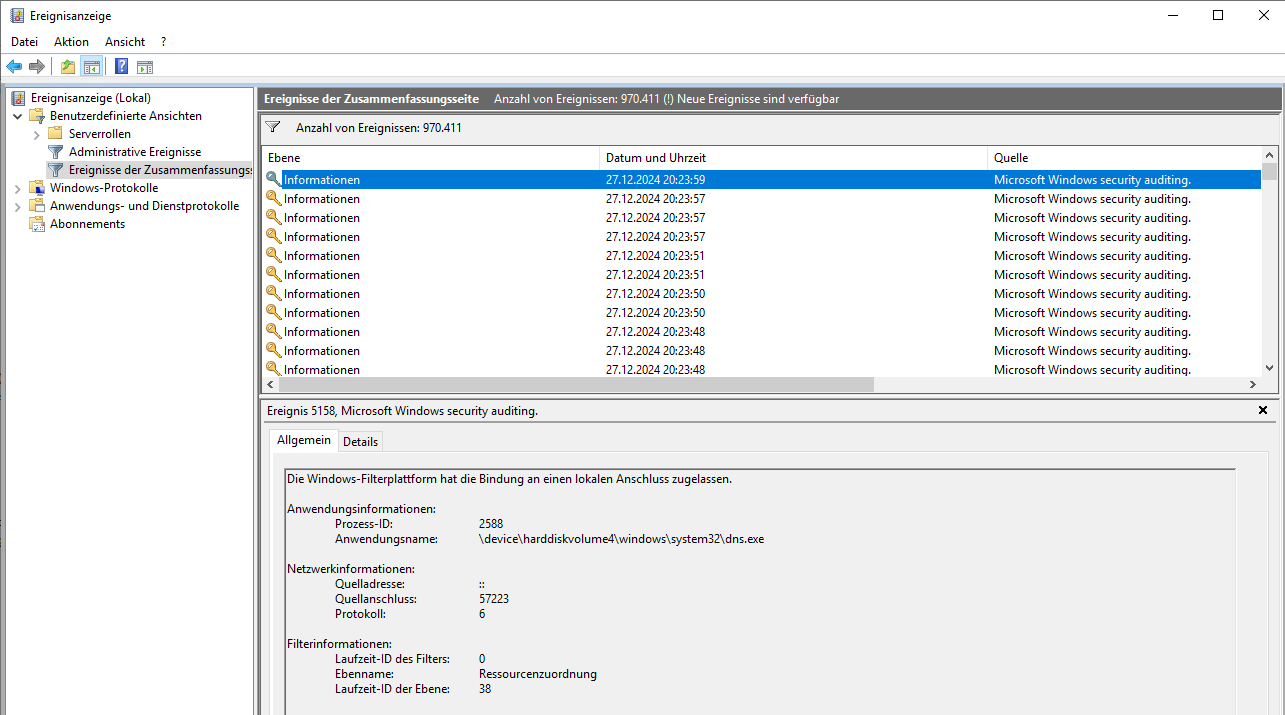
Meine Systeme protokollieren diese Informationen, da ich die Windows Firewall-Logs in das Eventlog umleite. Dazu nutze ich eine Advanced Audit Policy innerhalb einer Gruppenrichtlinie:
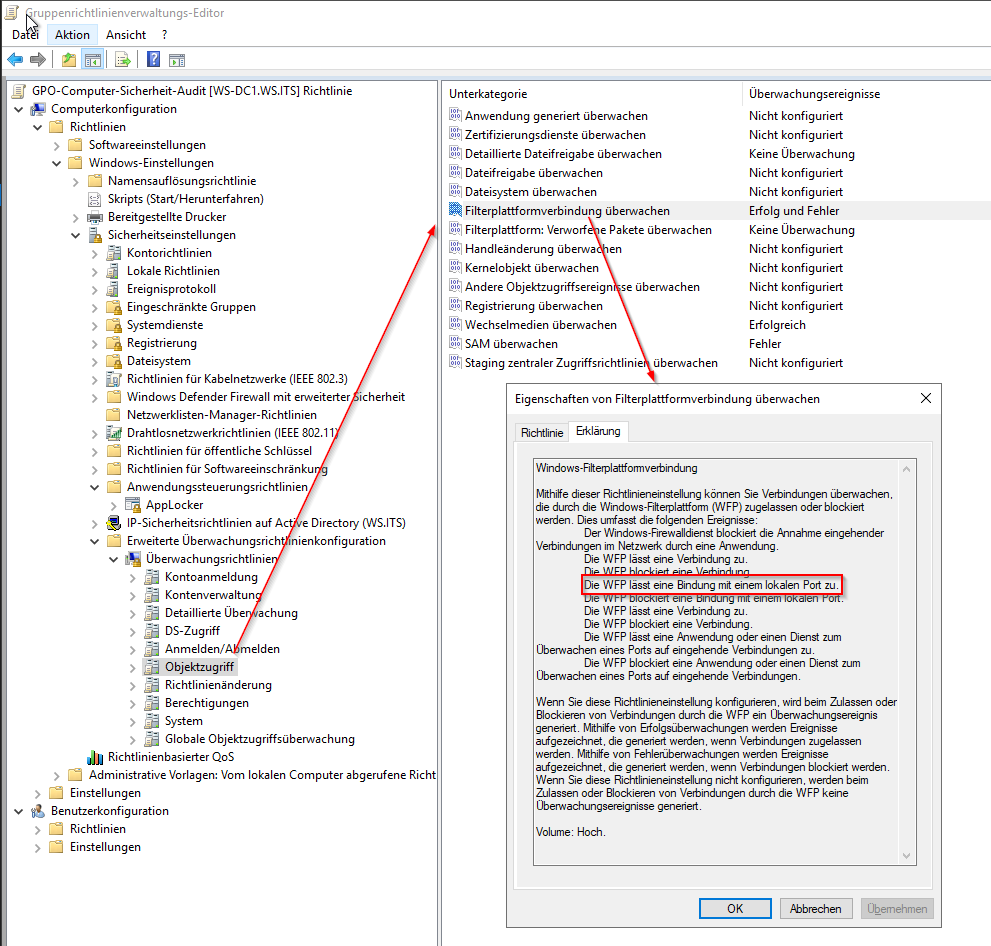
Leider gibt es in der GPO kein Feintuning: Ich kann das Logging nur ein- oder ausschalten. Und die anderen Logs der Windows Firewall können bei forensischen Analysen sehr nützlich sein! Daher ist das Deaktivieren der Audit-Policy keine Option.
Aktivierung eines drop_events im processor der Agent Policy
Ich muss also dafür sorgen, dass diese Events nicht vom Elastic Agent ausgelesen und zum ElasticSearch übertragen werden. Das lässt sich in der Agent Policy konfigurieren. Da ich diese Portbinding-Events generell nicht benötige, konfiguriere ich meine bestehende Agent Policy, die für alle Windows Systeme wirkt. Diese finde ich unter Management\Fleet\Agent-Policies:
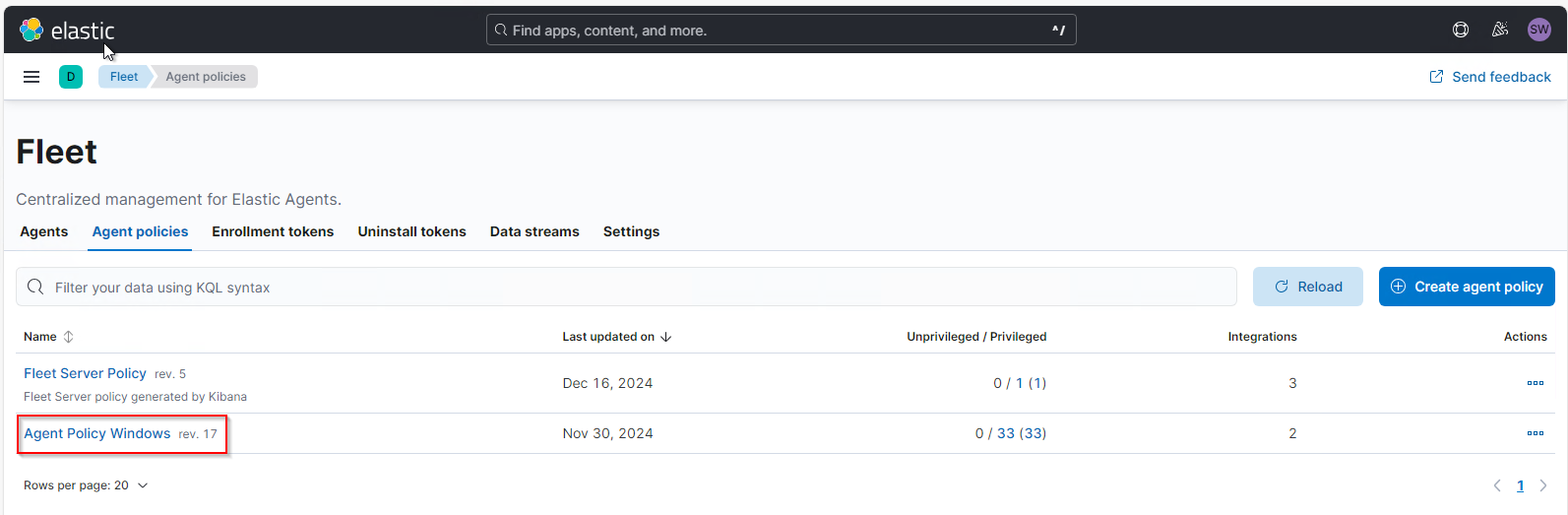
In der Policy sind aktuell 2 Integrationen vorhanden. Die Security Eventlogs werden von der system-1 geladen:
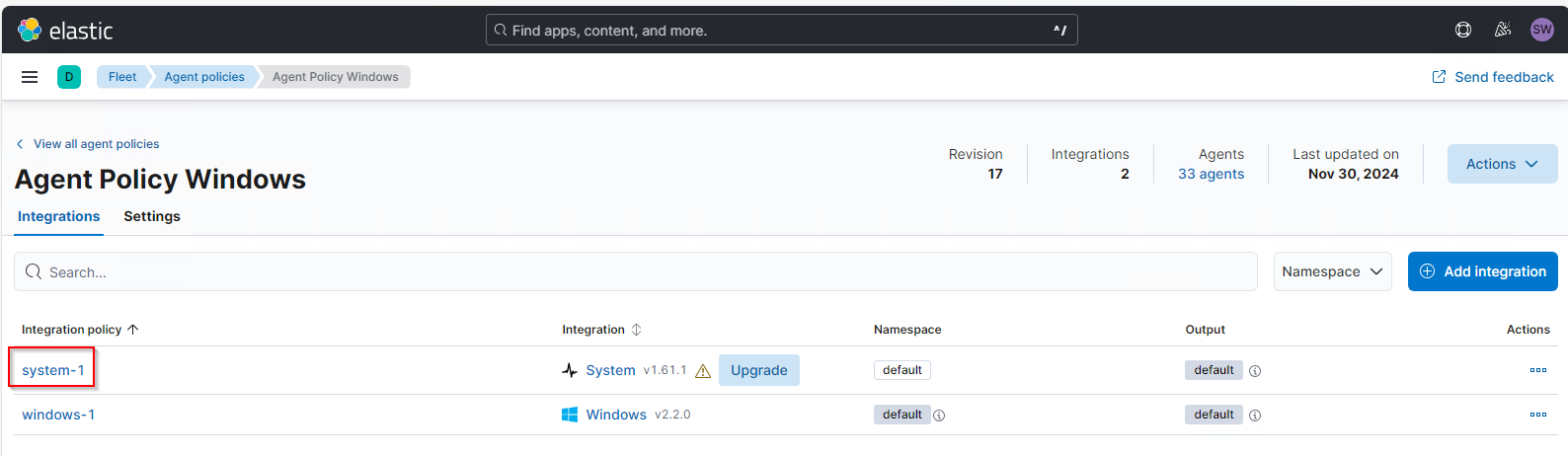
In der Konfigurationsseite der Integration suche ich den „Security Channel“ des Windows Eventlog und dort den Eintrag „Processors“. Hier kann ich definieren, welche Events z.B. verworfen werden sollen. Eine Anleitung dazu liefert der Hersteller hier: Define processors | Metricbeat Reference [8.17] | Elastic
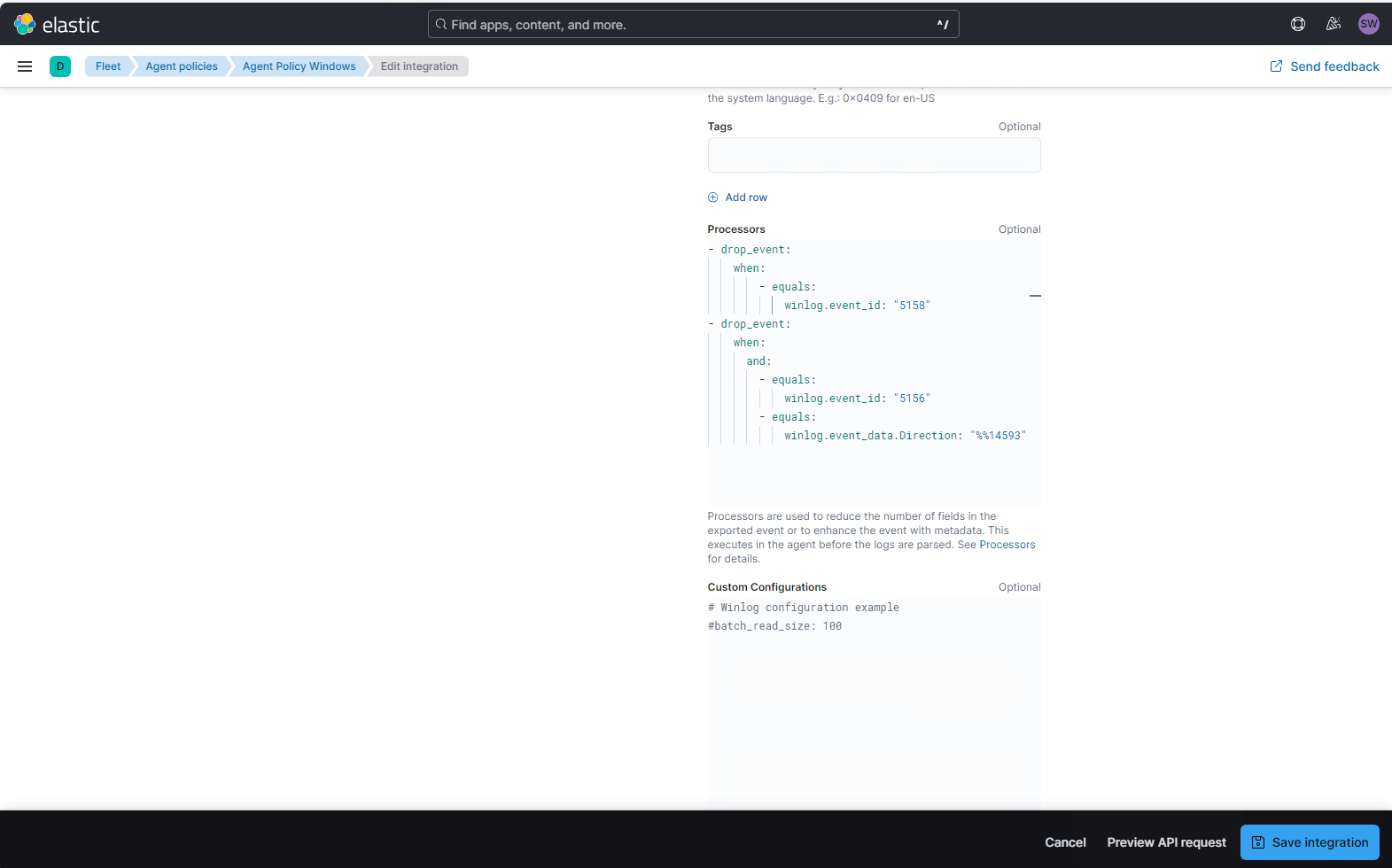
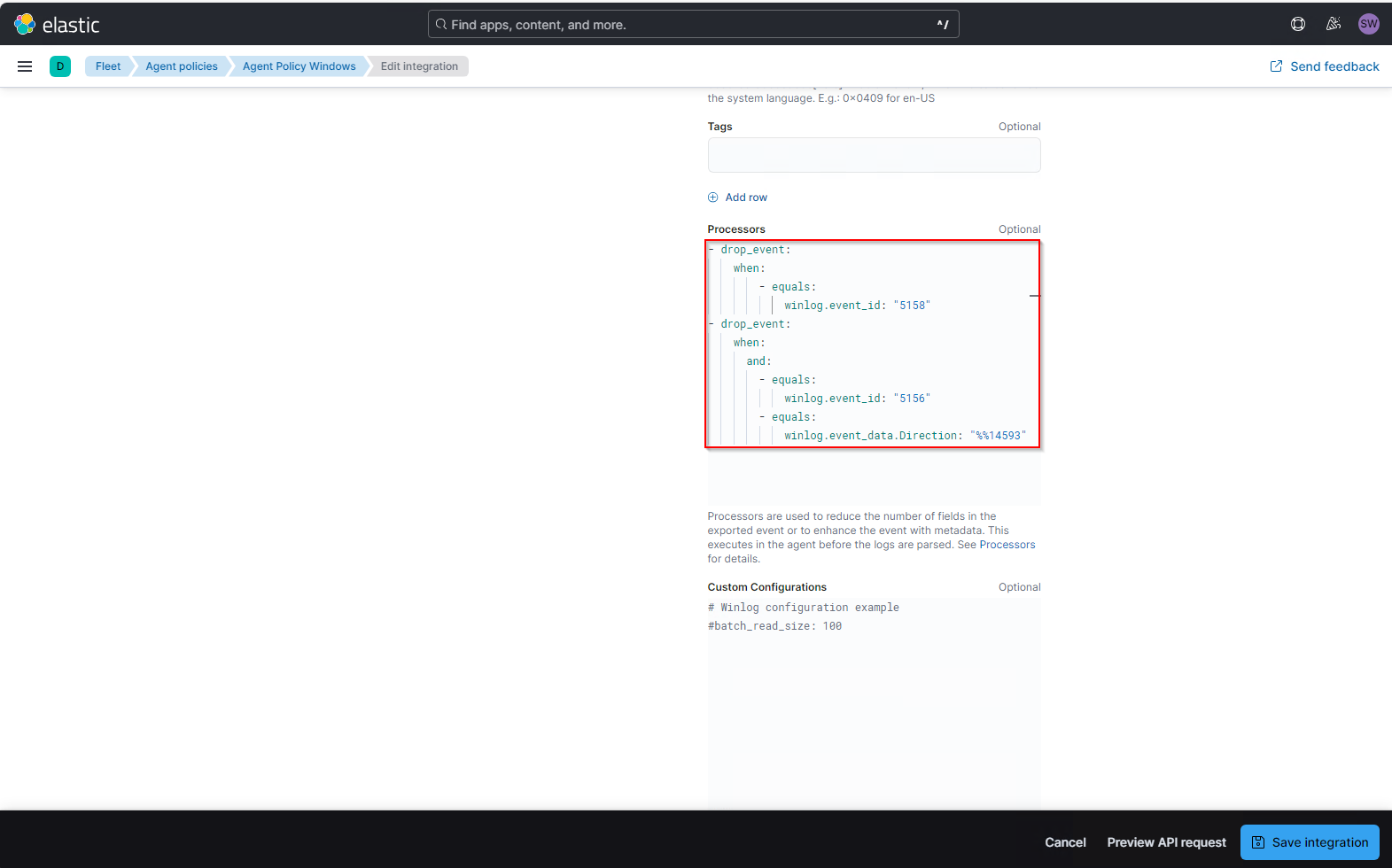
Nach ein paar Versuchen habe ich die Yaml-Anweisung für den Event-drop eingebaut und bei der Gelegenheit gleich noch ein zweites Event ausgefiltert:
- drop_event:
when:
- equals:
winlog.event_id: "5158"
- drop_event:
when:
and:
- equals:
winlog.event_id: "5156"
- equals:
winlog.event_data.Direction: "%%14593"Hier werden also 2 unterschiedliche Event IDs aus dem Security Eventlog gelöscht:
- entweder Events mit der ID 5158
- oder Events mit der ID 5156, wenn diese die Direction „%%14593“ enthalten. Das sind durch die Windows Firewall zugelassene, ausgehende Verbindungen
Den Filter speichere ich mit „save integration“. Dabei wird mir wieder angezeigt, das nun etliche Elastic Agents aktualisiert werden. Nun warte ich in mit einer angepassten Abfrage, ob noch Events mit der ID 5158 geliefert werden. Vorher kamen diese regelmäßig rein – teilweise mit sehr hohen Schüben von meinen DCs. Jetzt ist seit mehreren Minuten nichts mehr dabei 🙂
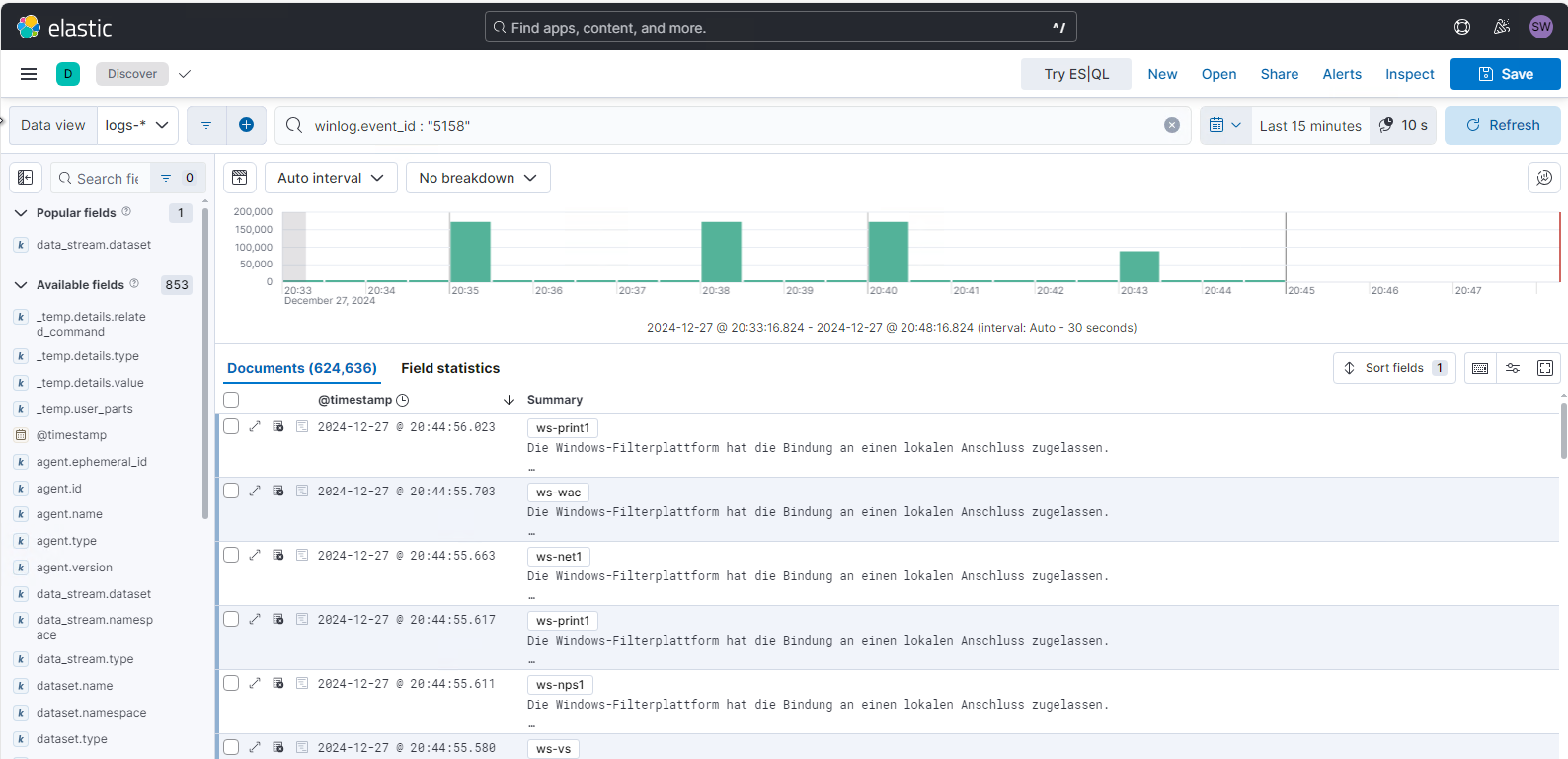
Suche nach der Ursache der 5158er Events
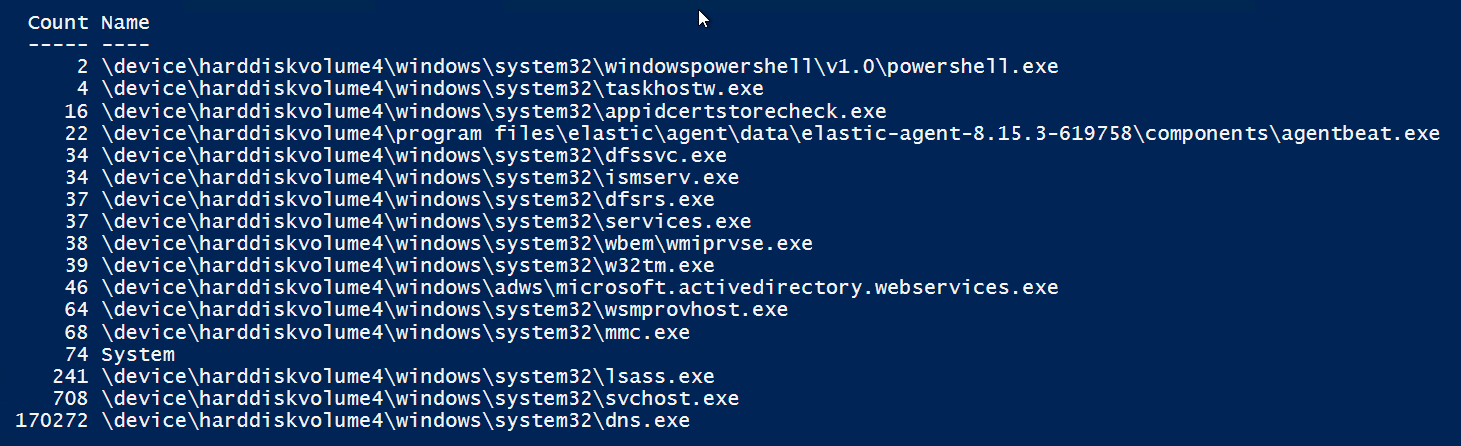
Aus Neugier möchte ich aber noch wissen, wo die extrem vielen Portbindungen her kommen. Da hilft mir wieder die PowerShell, die ich auf einem der Domain Controller ausführe. Die erste Zeile ermittelt alle Events mit der angegebenen ID aus dem Security Eventlog der letzten 3 Minuten und die andere Zeile extrahiert daraus die Anwendung und gruppiert nach dem Pfad. Dabei wird dann auch gezählt:
$Events = Get-WinEvent -FilterHashtable @{ logname="security" ; starttime=(get-date).AddMinutes(-3) ; id=5158 }
$Events | foreach-Object { $_.Properties[1].value } | group | sort count,name | ft count,name -AutoSizeDas Ergebnis überrrascht: Mein DNS-Service dreht wohl etwas hohl…
Kontrolle und Korrektur
Einige Stunden später prüfe ich, ob es die ungewünschten Events im Elastic noch gibt. Sie werden nicht mehr übertragen. Leider auch keine anderen Events aus dem Security-Eventlog mehr… Also prüfe ich erneut meinen processor Code. Die Yaml-Anweisung wurde in der Weboberfläche korrekt geparst. Dennoch scheint sie im Hintergrund einen Fehler zu verursachen. In einem Forum fand ich den entscheidenen Tipp: die Einrückungen müssen passen:
- Zeilen mit einem Minus voran müssen 2 Leerzeichen weiter als ihr Parent eingerückt werden
- Zeilen ohne ein Minus voran müssen 2 Leerzeichen weiter als ihr Parent eingerückt werden
Und da war mein Fehler. Ich hatte alles 2 Zeichen eingerückt. Und eventuell hat sich das System auch an den beiden drop_events gestört. Daher habe ich diese nun mit einem OR verbunden. Das ist meine neue Anweisung:
- drop_event:
when:
or:
- equals:
winlog.event_id: "5158"
- and:
- equals:
winlog.event_id: "5156"
- equals:
winlog.event_data.Direction: "%%14593"Damit werden nun wieder Events gesendet. Und das drop_event funktioniert nun auch. Hier sieht man auch deutlich, dass nun viel weniger Events übertragen werden. Und die Elastic-Agents haben die Daten sogar nachgeliefert – sofern diese noch in den Quellsystemen verfügbar waren 🙂
Zusammenfassung
Es ist nicht damit getan, einfach Agents auf die Log Source Systeme auszurollen. Man muss auch dafür sorgen, dass die richtigen Events ins SIEM gelangen. Dazu gehören die Audit-Einstellungen an der Quelle angepasst und die Agents müssen die relevanten Events filtern. Man sollte also regelmäßig mit seinen gesammelten Daten arbeiten. Nur so bekommt man ein Gefühl dafür.
Weitere Artikel findet ihr in meiner Serie „Bereitstellung eines Elastic SIEM„.
Stay tuned!