
Einleitung
Angriffe häufen sich und werden immer professioneller. Mit einer klassischen Sicherheitsstrategie alleine kommen wir nicht mehr weit. Daher müssen wir umdenken und uns neu ausrichten. In diesem Beitrag möchte ich mein Modell vorstellen. Es ist einfacher als das Mitre Att&ck Framework, kann aber auch mit diesem kombiniert werden.
Die moderne IT-Sicherheit basiert bei mir auf 3 Säulen: Hardening, Isolation und Detection & Response. In meinem Security-Workshop veranschauliche ich das in dieser Grafik:
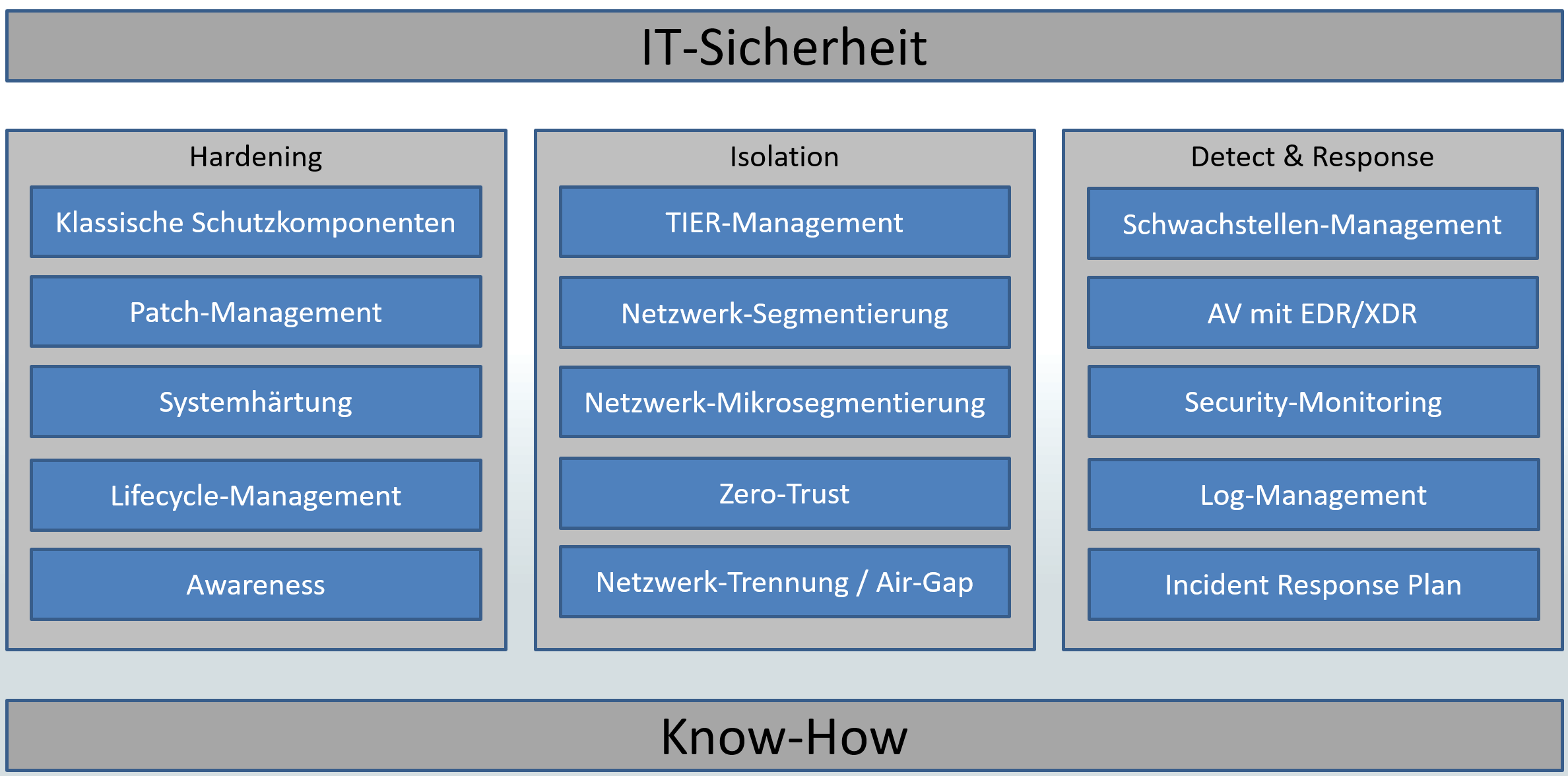
Die Basis des Ganzen ist natürlich das Wissen dazu in unseren Köpfen. 😉 In den folgenden Abschnitten könnt ihr meine Erläuterungen zu den einzelnen Bausteinen lesen.
Hardening
Das sind viele der klassischen Maßnahmen. Sie alle sind als absolute Basis zu verstehen! Und das nicht erst seit gestern 😉 Ich habe hier mal meine Hauptpunkte zusammengetragen:
- Klassische Schutzkomponenten: Hier zählen die echten Klassiker dazu, wie Malwarescanner, Windows Firewall und der Einsatz des Applocker.
- Patch-Management: Ohne Updates machen wir es dem Angreifer nur allzu leicht, denn jeden Monat werden viele Lücken in unseren Betriebssystemen und Anwendungen gefunden und vom Hersteller geschlossen. Nur durch eine gute Strategie gelingt es uns Administratoren, die erforderlichen Patches schnell, zuverlässig und automatisiert auf die Systeme auszubringen. Wie mein Patch-Management funktioniert, könnt ihr in diesem Beitrag unter „WSUS-UpdateApproval“ sehen: https://www.ws-its.de/serie-mig2019-ws-wsus/
- Systemhärtung: Windows und viele Standardanwendungen, wie Microsoft Office oder Browser kommen mit Standardeinstellungen daher. Diese sind eher auf Komfort als auf Sicherheit getrimmt. Das sollte mit z.B. Gruppenrichtlinien geändert werden.
- Lifecycle-Management: Ein Patch-Management kann nur funktionieren, wenn die Betriebssysteme und Anwendungen vom Hersteller auch noch unterstützt werden. Ich habe es schön öfter erlebt, dass veraltete Komponenten nicht mehr gepatcht werden können, weil Admins das End-of-Life nicht auf dem Schirm hatten. Man sollte über alle Software-Komponenten den Überblick haben und bereits bei der Einführung das Datum des End-of-Life erfassen. Und dann sollte man natürlich regelmäßig in diese Liste schauen und rechtzeitig Upgrades einplanen.
- Awareness: Wir sollten uns der Gefahr im Netz immer bewusst sein. Oft wird an die Sicherheit erst gedacht, wenn etwas passiert oder wenn eine neue Komponente schon länger in Betrieb ist. Hier müssen wir umdenken und zu einem Security-First kommen. Gerade beim Aufbau neuer Systeme ist es noch besonders leicht, die Sicherheit zu implementieren. Aber auch der geschulte Blick aus der Perspektive des Angreifers wird uns unterstützen.
Isolation
Die klassische Härtung alleine reicht schon lange nicht mehr. Angreifer breiten sich oft schnell im Netz auf andere Systeme aus, denn nur so können sie ihre Ziele erreichen: möglichst komplette Verschlüsselung oder die Kontrolle über kritikale Systeme. Hier hilft nur eine Isolation. Das sind meine Ansätze:
- Tier-Management: Wenn wir uns als Admins mit einer Kennung privilegiert auf allen Systemen bewegen können, dann tun wir das auch. Nur dann genügt eine Anmeldung auf einem kompromittierten System aus, um den Angreifer Zugriff auf unsere Admin-Identität zu gewähren. und dann wird er/sie unsere Rechte zur Ausbreitung auf andere Systeme nutzen. Mit einem administrativen Tier-Modell verhindern wir technisch, dass wir mit einer Kennung auf allen Systemen administrieren können. Meinen Ansatz hierfür könnt ihr euch hier ansehen: https://www.ws-its.de/psscript-ad-securityscopes/
- Netzwerk-Segmentierung: Was das Tier-Management auf der Rechteebene erledigt, das schafft die Netzwerk-Segmentierung auf Netzwerkebene. Müssen wir z.B. wirklich auf jeden Server von jedem Netzwerkgerät über RDP, SMB, WinRM, SSH, … zugreifen können? Wenn wir das können, dann kann es auch ein Angreifer! Durch eine Netzwerk-Segmentierung schaffen wir die Basis für zentrale Regelwerke, wer wann mit wem kommunizieren kann. Das klingt nach viel Arbeit. Und das ist es auch. Aber Angreifer werden an dieser hohen Hürde schnell scheitern bzw. deren Möglichkeiten werden schnell sehr übersichtlich. 🙂
- Netzwerk-Mikrosegmentierung: Im Idealfall kann kein System ein anderes erreichen, ohne durch die zentrale Firewall zu gehen. Dass würde aber bedeuten, dass jedes System in einem eigenen Netzwerksegment stehen muss. Der Aufwand hierfür wäre maßlos. Also fassen wir lieber gleichartige Systeme in Gruppen zusammen und packen diese in Netzwerksegmente. Dann brauchen wir nur noch den Schutz innerhalb der Gruppennetze. Mit z.B. der zentral steuerbaren Windows Firewall lässt sich das sehr einfach abbilden.
- Zero-Trust: Ui, wo fange ich bei diesem Buzzword an? Hier zählen so viele Komponenten dazu. Im Prinzip geht es um ein gesundes Misstrauen gegenüber allem. Wir unterstellen also, dass jeder interne Benutzer und jedes interne Gerät irgendwann kompromittiert sein könnte. Damit der Schaden möglichst gering ausfällt, sollte jeder Benutzer und jedes Gerät daher nur genau die Rechte erhalten, die für die Arbeit erforderlich sind (Least Privilege, JEA Just-Enough-Administration). Besser wäre es noch, diese Privilegien auf Zeit bzw. Bedarf einzuschränken (JIT Just-in-Time). Hier findet ihr mein Basis-Script für ein JIT im Windows AD: https://www.ws-its.de/psscript-pam-admingui/. Und natürlich müssen Zugriffe und Sitzungen permanent überwacht werden. Nur weil ein Benutzer zum Zeitpunkt der Anmeldung sauber war gilt das nicht für die gesamte Sitzung.
- Netzwerk-Tennung (Air-Gap): Bestimmte Komponenten sollten vom normalen Office-Netz abgekoppelt sein, denn selbst eine gute Netzwerksegmentierung hat ihre Übergangspunkte, die ein Angreifer finden wird. Wenn möglich, dann sollten z.B. Produktionsnetze vom Office-Netz physikalisch getrennt sein. Aber auch z.B. Backupsysteme könnten durch Einbahn-Verbindungen für Angreifer unerreichbar werden. Eine physikalische Trennung ist natürlich der Optimalfall. Aber auch kreative Konzepte sind denkbar: Mein Backup-Server z.B. ist im Netzwerk nicht erreichbar, da er sich nicht ansprechen lässt. Aber er kann sich über das Netzwerk die Infos von den Sicherungsquellen ziehen. Der Adminzugriff ist nur über die Hardware darunter möglich, wenn man in meinem „RZ“ ist. Zudem fährt das System vor der Sicherung und der Wartung automatisch hoch und danach automatisch herunter. Das minimiert das Zeitfenster für Angreifer im Schnitt auf ca. 20 Minuten pro Tag (Hinweis: Das ist mein 2. Backupsystem, das ausschließlich Nutzdaten (Dateien, Mailboxexporte) sichert, die dann auch ohne Infrastruktur wieder geladen werden können. Der 1. Backupserver läuft 24/7 durch und sichert zusätzlich auch die Betriebssysteme)
Detection & Response
Die Isolation ist die Ideale Erweiterung zur klassischen Härtung. Mit ihr ist es für Angreifer schon sehr schwer, sich auszubreiten. Dennoch gibt es hier 2 Punkte zu beachten:
- Wir können Lücken in der Härtung bzw. der Isolation haben. Einen 100%-Schutz wird es nie geben. Und wenn wir oder ein Kollege nur einen schlechten Tag bei der Konfiguration hatten, dann gibt es z.B. eine Lücke in der Firewall, die T0-Adminkennung ist in einer Tier2-Gruppe gelandet oder eine GPO greift z.B. nicht auf alle Systeme.
- Angreifer sind keine Script-Kiddies mehr. Die Industrie hinter den Angriffen verdient Milliarden pro Jahr. Das sind extrem professionelle Köpfe, die „unser Bestes“ wollen.
Irgendwann wird also der Tag kommen, an dem die ersten beiden Säulen versagen. Und dann (bzw. besser vorher) muss die dritte greifen: Detection & Response. Hier zähle ich folgende Komponenten dazu:
- Schwachstellen-Management: Mir passiert es immer wieder. Selbst oder vielleicht auch gerade wegen dem automatisierten Patch-Management kommen immer mal Updates nicht auf den Zielsystemen an. Ich denke: „Cool, ich bin sicher. Denn ich installiere Patches vollautomatisch“. Und der Angreifer freut sich. Ein Schwachstellen-Management sollte immer den unabhängigen Blick über alle Systeme schweifen lassen und Abweichungen vom gewünschten Zustand finden und melden. Das lässt sich je nach Hersteller auch für Konfigurationsprüfungen nutzen. So bekommt man auch schnell mit, ob z.B. Gruppenrichtlinien nicht mehr am Zielsystem ankommen.
- Malwarescanner mit EDR/XDR: Der klassische Malwarescan genügt nicht mehr. Ich selbst bezeichne mich gerne als Hobby-Programmierer und mir gelingt es immer wieder, dass selbst professionelle Scanner meine Malware übersehen. Klar, bei den ersten Opfern kann ein neuer Schadcode nicht in den AV-Signaturen stehen. Enhanced/Extended Detection and Response im Malwarescanner arbeitet meist mit Verhaltensanalysen und kombiniert mehrere scheinbar harmlose Einzel-Events zu einem bedrohlichen Incident, der dann dank Response auch automatisiert behandelt werden kann. Auch eine Schwarmintelligenz ist Teil dieses Gedanken. In meiner Kiste obskurer Ideen hab ich nur eine Möglichkeit gefunden, EDR auszutricksen. Und zu dieser gehört ne Menge Glück dazu…
- Log-Management & Security Monitoring: Leider hab ich es schon 2 Mal erlebt: Der Angreifer war erfolgreich und hat erheblichen Schaden angerichtet. Und dann gehen die Fragen los: Wie ist der Angreifer ins Netz gekommen? Wie hat er/sie die Kontrolle übernehmen können? Seit wann ist der Angreifer im Netz? Welche Daten und Systeme sind betroffen? Ohne eine Antwort auf diese Fragen wird es z.B. schwer, ein „sauberes“ Backup für die Wiederherstellung zu finden bzw. die ausgenutzten Schwachstellen zu fixen. Daher sollten von allen Systemen proaktiv wichtige Ereignisse zu einem zentralen System geschickt werden. Dieses sollte ebenso wie z.B. das Backup-System möglichst nicht an das Active Directory angeschlossen sein. Hier könnte man nach einem Angriff wertvolle Informationen für die oben genannten Fragen finden. Aber auch für eine Angriffserkennung sind die Daten nutzbar, indem man für Standard-Szenarien automatisierte Abfragen laufen lässt. Liefern diese Ergebnisse, dann könnte sich ein Angreifer im Netz befinden. Vielleicht genügt die Zeit, um größeren Schaden abzuwenden.
- SIEM: Ein Security Information and Event Management System ist die logische Finalisierung des Security Monitorings und basiert ebenfalls auf den gesammelten Daten im Log-Management. Hier werden aber ähnlich wie beim EDR Events übergreifend analysiert und Schlussfolgerungen gezogen. Z.B. könnte nach 100.000 fehlerhaften Anmeldeereignissen für eine Benutzerkennung eine erfolgreiche im Log-Management aufgezeichnet werden. Ein SIEM könnte daraus ein erfolgreichen Brute-Force-Angriff erkennen. Der Aufwand beim Betrieb einer solchen Lösung ist aber nicht zu unterschätzen! Und das System nutzt nichts, wenn niemand in die Meldungen (auf als Offense bezeichnet) rein schaut.
Ach ja: SIEM könnte mit SOAR (Security Orchestration Automation and Response) auch automatisiert Gegenmaßnahmen einleiten. - Incident Response Plan: Nach den vielen technischen Möglichkeiten brauchen wir aber vor allem eines: Einen Plan. Wer hat schon Lust auf einen „Headless Chicken Mode“, wenn ein Angriff erkannt wird. Und in einer solchen Stresssituation haben wir keine Zeit zum Überlegen. Also bereitet euch VOR dem Angriff darauf vor: Wer muss wann kontaktiert werden? Welche Maßnahmen sind wann von wem durchzuführen? Wo liegen unsere Logs für eine genaue Analyse? usw. Ebenso würde ich dringend empfehlen, regelmäßig intern solche Angriffsszenarien zu simulieren und die Durchführung des Plans zu üben. Nur so bekommen wir die erforderliche Routine in die Köpfe der Beteiligten. Die vielen Mitglieder der Freiwilligen Feuerwehr üben auch immer wieder den Ernstfall. Das sollte uns ein Beispiel sein!
Wo soll ich beginnen?
In der IT-Sicherheit werden wir nicht nur einige Stunden oder Euro versenken. Eine stabile Abwehr von Bedrohungen bedeutet einigen Aufwand. Diesen würde ich aber jedem empfehlen. Und es muss ja nicht gleich das große Paket sein…
Beginnt bei den klassischen Härtungen und setzt dort vor allem die „Quick-Wins“ um. Die kosten nicht viel und sind schnell implementiert. Arbeitet euch dann in der Isolation weiter vor. Auch hier gibt es schnelle Erfolge: Isoliert z.B. beim Tier-Management erst einmal die wenigen, hochprivilegierten Tier-0-Kennungen vom Rest. Gleiches gilt bei der Netzwerk-Segmentierung: stellt erst einmal die kritikalen Assets (Backup, vCenter, Domain Controller, PKI, …) in neue Netze und sichert diese ab. Nicht jeder 0815-Server muss segmentiert sein, damit die Maßnahme Wirkung zeigt. Und bei der Detection & Response ist der Malwarescanner die erste Wahl. Hier haben die Hersteller oft schon viele Innovationen integriert, die schnelle Erfolge zeigen. Ein SIEM sollte eher später kommen. Bereitet euch aber auf das Logging vor. Selbst ein lokales Aufzeichnen von Sicherheitsereignissen (Advanced Audit Policy mit Gruppenrichtlinie; Ausrollen vom sysmon: https://www.ws-its.de/implementierung-von-sysmon/) kann helfen.
Wir haben bereits viele der vorgestellten Komponenten aufgebaut bzw. in der Implementierung. Diese Woche hatten wir Pentester in unserem Netzwerk. Und ich wünsche jedem von euch dieses tolle Gefühl, wenn man den „Angreifer“ in der ersten Stunde von der Automatik gemeldet bekommt und dann nahezu vollständig deren Vorgehen rekonstruieren kann. Und alleine das Wissen, wie die sich die Zähne an den Schutzmechanismen ausbeißen… Einfach genial!
Stay tuned!