
Ich nutze die Powershell gerne für Automationen – im aktuellen Fall wollte ich in einem Intervall eine aktive Logdatei nach bestimmten Begriffen durchsuchen und daraus Aktionen ableiten. Die Logik für das Script war schnell gefunden. Doch die Performance war unterirdisch. Es musste eine Lösung her…
Mein Script sollte folgende Arbeitsschritte in einer Dauerschleife ausführen:
- Lies die Textdatei mit get-content ein
- Durchsuche die Zeilen im RAM nach den Suchbegriffen (Select-String)
- starte die Aktionen
Kleine Logfiles kann man so recht einfach verarbeiten. Nur leider wurden meine Logfiles auch gerne einmal 100MB groß. Und da hat die PowerShell leider ihre Grenzen – das Einlesen dauert einfach zu lange. Im Folgenden beschreibe ich meine 3 Lösungsansätze.
Inhaltsverzeichnis
Lösungsansatz „Get-Content -tail“
Get-Content liest die gesamte Datei ein. Mein Beispiel umfasst 10 Zeilen:
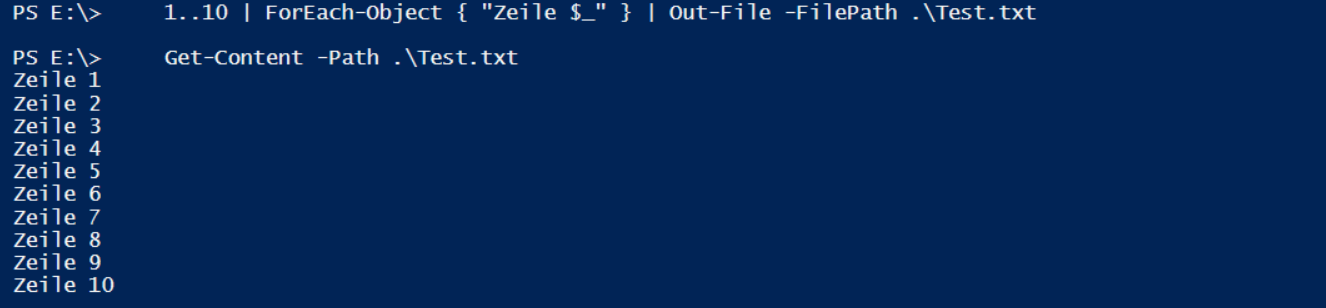
Mit dem Parameter -Tail kann die Anzahl der letzten Zeilen angegeben werden:

Damit könnte man nur die letzten Zeilen eines Logfiles einlesen – aber woher soll ich die Anzahl der neuen Zeilen seit dem letzten Lauf kennen? Das ist nur bei statischen Dateien eine Lösung ☹
Lösungsansatz „Select-Object -skip“
Wie wäre es mit einen Skip? Beim ersten Einlesen werden keine Zeilen mit skip übersprungen. Nach der Aktion wird einfach die aktuelle Zeilenanzahl gespeichert und beim nächsten Lauf übersprungen. Das wäre der erste Lauf:
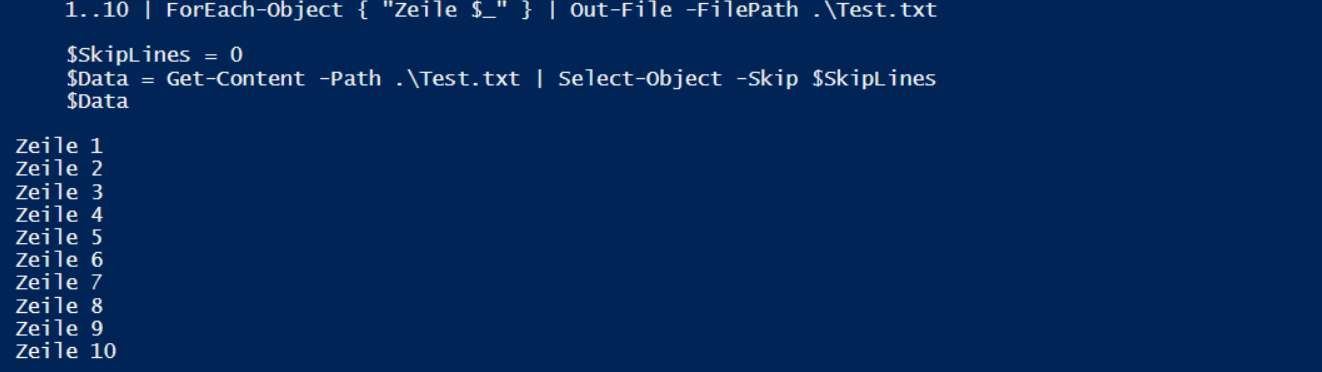
Es wurden alle 10 Zeile eingelesen. Vor dem nächsten Lauf werden weitere 5 Zeile angefügt (das Logfile wächst). Beim Einlesen werden die ersten 10 Zeilen übersprungen:
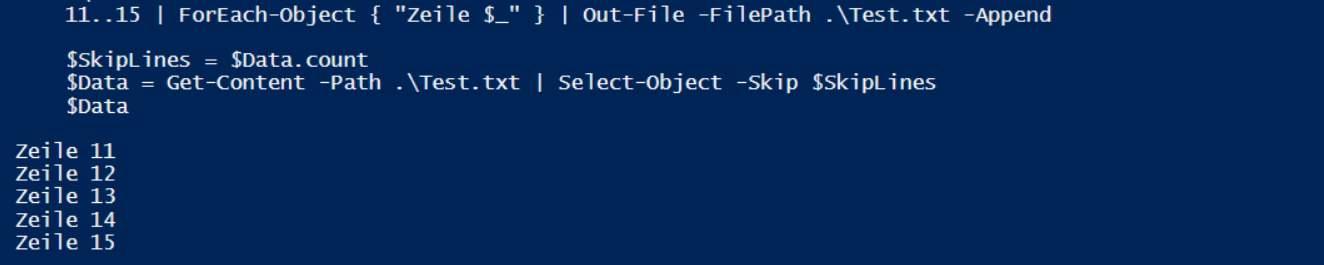
Nur leider müssen ALLE 15 Zeilen eingelesen werden. Das Skip ist eine Option NACH der Pipeline… Wie sich das zeitlich auswirkt könnt ihr an diesem Code sehen. Meine Demodatei umfasst 100.000 Zeilen. Alleine das Erstellen dauert schon etliche Sekunden:

und belegt einige Systemressourcen:
Die zeitliche Bewertung nehme ich mit Measure-Command vor. Dieses cmdlet misst die Zeit für die Ausführung eines Scriptblocks und gibt diese als TimeSpan aus.
Beim ersten Lauf müssen alle 100.000 Zeilen gelesen werden . der Skipwert ist 0:

Das Lesen der 100.000 Zeilen hat hier 3,42 Sekunden gedauert. Das klingt nicht nach viel – die Datei ist aber aktuell auch nur 5MB groß. Bei 100MB Größe ist der Aufwand 20x so hoch und entspricht somit schon über einer Minute!!!
Vor dem zweiten Lauf füge ich einige Zeilen an die Testdatei an:

Der Skipwert wird mit der Anzahl der bereits gelesenen Daten ($Data.count) belegt:

Die 10 neuen Zeilen benötigen die volle Lesezeit!!! Das ist keine Lösung! ☹
Lösungsansatz „.net StreamReader“
Da es aktuell keine cmdlets mit der von mir benötigten Funktion gibt, greife ich nun auf .net zurück. Dort gibt es den StreamReader. Dieser kann Daten sehr viel schneller verarbeiten. Dafür sind mehrere Codezeilen erforderlich:

Der Datenstrom wird in der Variable $Stream geladen und mit der Methode Readline() gelesen.
Natürlich sind das nicht alle Optionen. Sehr interessant ist die Eigenschaft BaseStream.Position, mit der ein Offset angegeben werden kann. Mit diesem Wert kann ich Daten beim Lesen überspringen! Das sieht dann so aus:

Aber ist das nun schneller? Der Test mit meiner 100.000 Zeilen-Datei wird es zeigen. Beim ersten Lauf werden alle 100.010 Zeilen eingelesen (die 10 extra Zeilen vom ersten Beispiel hab ich einfach mal mitgenommen):
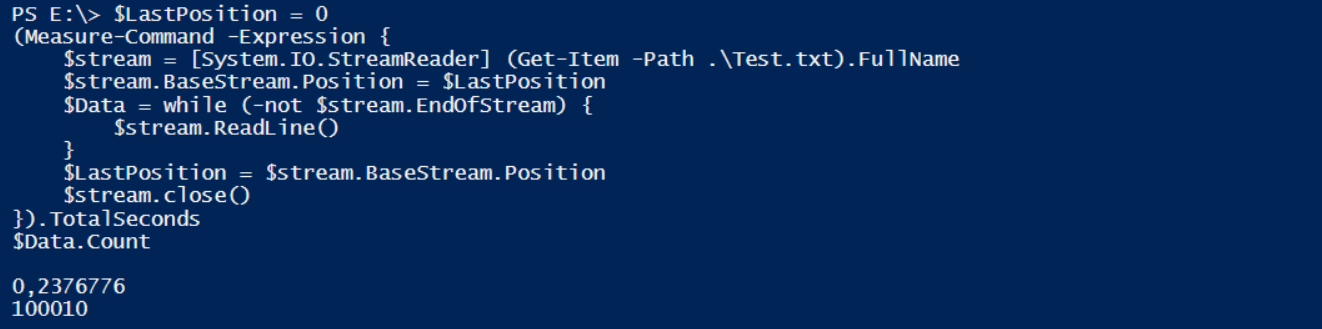
Das Einlesen der 100.010 Zeilen hat 0,23 Sekunden gedauert! Das ist 15x schneller als get-content gewesen!
Diese 100.010 Zeilen ergeben eine Basestream.Position von 600602 – das ist die Summe der Bytes, die gelesen wurden!

Nun füge ich weitere 10 Zeilen an:

Und der zweite Lauf überspringt die 5,72MB vom ersten Lauf…
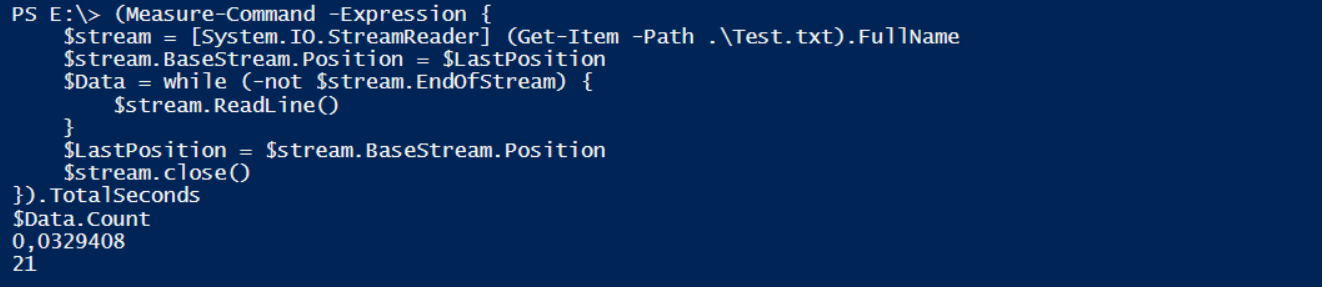
… und ließt die 10 neuen Zeilen (und den dafür erforderlichen Zeilenumbruch -> 11 Zeilen) in 33 Milisekunden ein!!! Das ist die Lösung!
Hier findet ihr das Demo-Script zum selber probieren: Show-StreamReaderPerformance
Viel Spaß beim Scripten! Stay tuned!